16.1 Char-RNN을 사용해 셰익스피어 문체 생성하기
Char-RNN을 사용해 한 번에 한 글자씩 새로운 텍스트를 생성할 수 있다. Char-RNN 모델을 어떻게 만드는지 단계별로 알아본다.
16.1.1 훈련 데이터셋 만들기
케라스의 get_file() 함수를 사용해 안드레이 카패시의 Char-RNN 프로젝트에서 셰익스피어 작품을 모두 다운로드한다.
shakespeare_url = 'https://homl.info/shakespeare'
filepath = keras.utiles.get_file('shakespeare.txt', shakespeare_url)
with open(filepath) as f:
shakespeare_text = f.read()다음으로 모든 글자를 정수로 인코딩해야 한다. 케라스의 Tokenizer 클래스를 사용하여 먼저 해당 객체를 텍스트에 훈련시킨다. 텍스트에서 사용된 모든 글자를 찾아 각기 다른 글자 ID에 매핑한다.
참고로 ID는 1부터 시작한다. 0은 마스킹할 때 사용한다.
tokenizer = keras.preprocessing.text.Tokenizer(char_level=True)
tokenizer.fit_on_texts(shakespeare_text)char_level=True 로 지정하여 단어 수준 인코딩 대신 글자 수준 인코딩을 만든다. 아래처럼 문장을 글자 ID로 인코딩하거나 반대로 디코딩할 수도 있다.
tokenizer.texts_to_sequences(['First'])
# [[20, 6, 9, 8, 3]]
tokenizer.sequences_to_texts([[20, 6, 9, 8, 3]])
# ['f i r s t']
max_id = len(tokenizer.word_index) # 고유 글자 개수
dataset_size = tokenizer.document_count # 전체 글자 개수이제 전체 텍스트를 인코딩하여 각 글자를 ID로 나타내보자(1에서 39까지 대신 0에서 38가지 ID를 얻기 위해 1을 뺀다).
[encoded] = np.array(tokenizer.texts_to_sequences([shakespeare_text])) - 116.1.2 순차 데이터셋을 나누는 방법
시계열을 다룰 땐 보통 시간에 따라 데이터셋을 나눈다. 암묵적으로 RNN이 과거(훈련 세트)에서 학습하는 패턴이 미래에도 등장한다고 가정한다. 다시 말해 시계열 데이터가 (넓은 의미에서) 변하지 않는다(stationary)고 가정한다.
정상 시계열(stationary time series)은 평균, 분산, 자기상관(autocorrelation, 어떤 간격으로 나눈 시계열 값 사이의 상관관계)이 시간에 따라 변하지 않는 것을 의미한다. 트렌드나 주기적 패턴을 가진 시계열은 이에 해당되지 않는 반면, RNN은 유연하여 트렌드 및 주기적 패턴을 학습할 수 있다.
셰익스피어 데이터로 돌아가서 텍스트의 처음 90%를 훈련 세트로 사용하고, 나머지는 검증 세트와 테스트로 사용한다. 여기서 한 번에 한 글자씩 반환하는 tf.data.Dataset 객체를 만든다.
train_size = dataset_size * 90 // 100
dataset = tf.data.Dataset.from_tensor_slices(encoded[:train_size])16.1.3 순차 데이터를 윈도 여러 개로 자르기
훈련 세트는 백만 개 이상의 글자로 이루어진 시퀀스 하나이므로 window() 메서드를 사용해 작은 많은 텍스트 윈도로 변환한다. 이 데이터셋의 각 샘플은 전체 텍스트에서 매우 짧은 부분 문자열이고, RNN은 이 부분 문자열 길이만큼만 역전파를 위해 펼쳐진다. 이를 TBPTT(truncated backpropogation through time)라고 부른다.
n_steps = 100
window_length = n_steps + 1
dataset = dataset.window(window_length, shift=1, drop_remainder=True)기본적으로 window() 메서드는 윈도를 중복하지 않음
shift=1로 지정하면 가장 큰 훈련 세트를 만들 수 있음
ex) 첫 번째 윈도: 0~100번째 글자 / 두 번째 윈도: 1~101번째 글자
drop_remainder=True로 지정하면 모든 윈도가 동일한 길이의 글자를 포함
window() 메서드는 각각 하나의 데이터셋으로 표현되는 윈도를 포함하는 데이터셋을 만든다. 리스트의 리스트와 비슷한 중첩 데이터셋(nested dataset)이다. 다만, 모델은 텐서를 원하기 때문에 훈련에 중첩 데이터셋을 바로 사용할 수는 없다. 따라서 플랫 데이터셋(flat dataset)으로 변환하는 flat_map() 메서드를 호출한다.
ex) flat화: {{1, 2}, {3, 4, 5, 6}} -> {1, 2, 3, 4, 5, 6}
flat_map(lambda ds: ds.batch(2)) -> {[1, 2], [3, 4], [5, 6]}
dataset = dataset.flat_map(lambda window: window.batch(window_length))경사 하강법은 훈련 세트 샘플이 동일 독립 분포일 때 가장 잘 작동하므로 윈도를 섞어야 한다.
batch_size = 32
dataset = dataset.shuffle(10000).batch(batch_size)
dataset = dataset.map(lambda window: (windows[:, :-1], windows[:, 1:]))
이제 글자를 인코딩할 차례인데, 여기선 고유한 글자 수가 적기 때문에 원-핫 벡터를 사용한다.
dataset = dataset.map(lambda X_batch, Y_batch: (tf.one_hot(X_batch, depth=max_id), Y_batch))
dataset = dataset.prefetch(1)prefetch(1): 1개의 배치를 더 만듦으로써 학습할 배치를 미리 준비시키는 것(성능 개선 및 속도 향상)
16.1.4 Char-RNN 모델 만들고 훈련하기
model = keras.models.Sequential([
keras.layers.GRU(128, return_sequences=True, input_shape=[None, max_id],
dropout=0.2, recurrent_dropout=0.2),
keras.layers.GRU(128, return_sequences=True,
dropout=0.2, recurrent_dropout=0.2),
keras.layers.TimeDistributed(keras.layers.Dense(max_id, activation='softmax'))
model.compile(loss='sparse_categorical_crossentropy', optimizer='adam')
history = model.fit(dataset, epochs=20)dropout: 입력 드롭아웃
recurrent_dropout: 은닉 상태 드롭아웃
16.1.5 Char-RNN 모델 사용하기
def preprocess(texts):
X = np.array(tokenizer.texts_to_sequences(texts)) - 1
return tf.one_hot(X, max_id)X_new = preprocess(['How are yo'])
Y_pred = model.predict_classes(X_new)
tokenizer.sequences_to_texts(Y_pred + 1)[0][-1]16.1.6 가짜 셰익스피어 텍스트를 생성하기
Char-RNN 모델을 사용해 새로운 텍스트를 생성하려면 먼저 초기 텍스트를 주입하고 모델이 가장 가능성 있는 다음 글자를 예측한다. 다시 이 글자를 텍스트 끝에 추가하고 늘어난 텍스트를 모델에 전달하여 다음 글자를 예측한다. 다만 이렇게 하면 같은 단어가 계속 반복되는 경우가 많다.
텐서플로의 tf.random.categorical() 함수를 사용해 모델이 추정한 확률을 기반으로 다음 글자를 무작위로 선택할 수 있다. categorical() 함수는 클래스의 로그 확률(로짓)을 전달하면 랜덤하게 클래스 인덱스를 샘플링한다. 생성된 텍스트의 다양성을 더 많이 제어하려면 온도(temperature)라고 불리는 숫자로 로짓을 나눈다.
def next_char(text, temperature=1):
X_new = preprocess([text])
y_proba = model.predict(X_new)[0, -1, :]
rescaled_logits = tf.math.log(y_proba) / temperature
char_id = tf.random.categorical(rescaled_logits, num_samples=1) + 1
return tokenizer.sequences_to_texts(char_id.numpy())[0]temperature
- 0에 가까울수록 높은 확률을 가진 글자 선택
- 반대로 높아질수록 모든 글자가 동일한 확률을 가짐
predict() 메서드 출력은 0과 1사이의 값을 가진다. 여기에 로그를 취하고 0에 가까운 temperature로 나눈 후 다시 지수함수로 복원하면 작았던 확률이 더 크게 작아진다. 즉 가장 높았던 확률을 가진 단어가 선택될 가능성이 더 높아진다.
그다음 next_char() 함수를 반복 호출하여 다음 글자를 얻고 텍스트에 추가해보자.
def complete_text(text, n_chars=50, temperature=1):
for _ in range(n_chars):
text += next_char(text, temperature)
return text16.1.7 상태가 있는 RNN
지금까진 상태가 없는 RNN(stateless RNN)만 사용했다. 훈련 반복마다 모델의 은닉 상태를 0으로 초기화하고, 타임 스텝마다 이 상태를 업데이트하고 마지막 타임 스텝 후에는 더 필요가 없기 때문에 버린다.
만약 RNN이 한 훈련 배치를 처리한 후 마지막 상태를 다음 훈련 배치의 초기 상태로 사용하면 어떨까? 이렇게 하면 역전파는 짧은 시퀀스에서 일어나지만 모델이 장기간 패턴을 학습할 수 있다. 이를 상태가 있는 RNN(stateful RNN)이라 한다.
상태가 있는 RNN은 배치에 있는 각 입력 시퀀스가 이전 배치의 시퀀스가 끝난 지점에서 시작해야 한다.
첫 번째 할일: 순차적이고 겹치지 않는 입력 시퀀스 만들기
가장 간단한 방법은 하나의 윈도를 갖는 배치를 만드는 것이다.
dataset = tf.data.Dataset.from_tensor_slices(encoded[:train_size])
dataset = dataset.window(window_length, shift=n_steps, drop_remainder=True)
dataset = dataset.flat_map(lambda window: window.batch(window_length))
dataset = dataset.batch(1)
dataset = dataset.map(lambda windows: (windows[:, :-1], windows[:, 1:]))
dataset = dataset.map(
lambda X_batch, Y_batch: (tf.one_hot(X_batch, depth=max_id), Y_batch))
dataset = dataset.prefetch(1)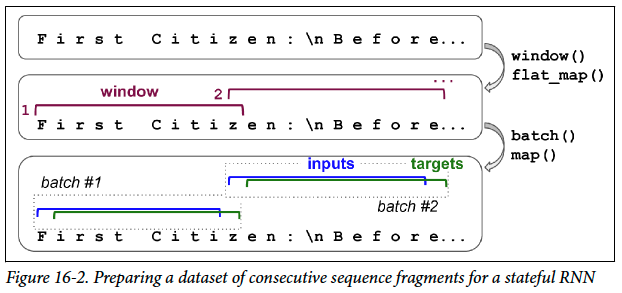
상태가 있는 RNN을 만들어보자.
1) 각 순환 층을 만들 때 stateful=True로 지정
2) 상태가 있는 RNN은 배치 크기를 알아야 함(배치에 있는 입력 시퀀스의 상태를 보존해야 하기 때문)
model = keras.models.Sequential([
keras.layers.GRU(128, return_sequences=True, stateful=True,
dropout=0.2, recurrent_dropout=0.2,
batch_input_shape=[batch_size, None, max_id]), # 입력 길이는 지정 X
keras.layers.GRU(128, return_sequences=True, stateful=True,
dropout=0.2, recurrent_dropout=0.2),
keras.layers.TimeDistributed(keras.layers.Dense(max_id, activation='softmax'))
])에포크 끝마다 텍스트를 다시 시작하기 전에 상태를 재설정해야 한다. 에포크가 끝날 때 현재 훈련 배치의 마지막 상태만 다음 훈련 배치 초기 상태로 이용하는 것이지, 계속해서 그 상태를 다음, 다다음 훈련 배치에 이어나가는 것이 아니다.
class ResetStatesCallback(keras.callbacks.Callback):
def on_epoch_begin(self, epoch, logs):
self.model.reset_states()model.compile(loss='sparse_categorical_crossentropy', optimizer='adam')
model.fit(dataset, steps_per_epoch=steps_per_epoch, epochs=50,
callbacks=[ResetStatesCallback()])16.2 감성 분석
IMDb 리뷰 데이터셋(전처리 완료)으로 감성 분석을 다루어보자.
(X_train, y_train), (X_test, y_test) = keras.datasets.imdb.load_data()- 각 리뷰는 넘파이 정수 배열로 표현
- 구두점을 모두 제거하고 단어는 소문자로 변환한 다음 공백으로 나누어 빈도에 따라 인덱스를 붙임
- 0: 패딩 토큰 / 1: SOS(start-of-sequence) / 2: 알 수 없는 단어
리뷰 내용은 아래와 같이 디코딩하여 확인 가능하다.
word_index = keras.datasets.imdb.get_word_index()
id_to_word = {id_ + 3: word for word, id_ in word_index.items()}
for id_, token in enumerate(('<pad>', '<sos>', '<unk>')):
id_to_word[id_] = token
''.join([id_to_word[id_] for id_ in X_train[0][:10]])실전 프로젝트에선 직접 텍스트를 전처리해야 한다. 크게 보면 4가지가 있다.
1. 공백을 사용해 단어 경계 구분
- 공백을 사용하지 않는 언어의 경우 적용 불가
2. 부분 단어(subword) 수준으로 텍스트를 토큰화하거나 복원하는 비지도 학습 방법
- 공백을 하나의 문자로 취급하기 때문에 언어 독립적
- ex) smartest -> smart + -est 로 쪼개 '-est'가 the most란 의미를 학습
3. 바이트 페어 인코딩(byte pair encoding)
- 부분 단어를 인코딩하는 방법의 일종
4. 텐서플로의 TF.Text 라이브러리
- 워드피스(wordpiece)를 포함한 다양한 토큰화 전략 구현
import tensorflow_datasets as tfds
datasets, info = tfds.load('imdb_reviews', as_supervised=True, with_info=True)
train_size = info.splits['train'].num_examples전처리 함수를 먼저 설계한다.
def preprocess(X_batch, y_batch):
X_batch = tf.strings.substr(X_batch, 0, 300)
X_batch = tf.strings.regex_replace(X_batch, b"<br\\s*/?>", b" ")
X_batch = tf.strings.regex_replace(X_batch, b"[^a-zA-Z']", b" ")
X_batch = tf.strings.split(X_batch)
return X_batch.to_tensor(default_value=b"<pad>"), y_batch그 다음 어휘 사전을 구축해야 한다.
from collections import Counter
vocabulary = Counter()
for X_batch, y_batch in datasets['train'].batch(32).map(preprocess):
for review in X_batch:
vocabulary.update(list(review.numpy()))좋은 성능을 내기 위해선 사전에 있는 모든 단어를 모델이 알아야 할 필요는 없다. 어휘 사전 중 가장 많이 등장하는 단어 10,000개만 남기고 삭제한다.
vocab_size = 10000
truncated_vocabulary = [
word for word, count in vocabulary.most_common()[:vocab_size]]이제 각 단어를 ID로 바꾸는 전처리 단계를 추가한다. 1000개의 oov(out-of-vocabulary) 버킷을 사용하는 룩업 테이블을 만든다.
words = tf.constant(truncated_vocabulary)
word_ids = tf.range(len(truncated_vocabulary), dtype=tf.int64)
vocab_init = tf.lookup.KeyValueTensorInitializer(words, word_ids)
num_oov_buckets = 1000
table = tf.lookup.StaticVocabularyTable(vocab_init, num_oov_buckets)룩업 테이블에서 단어 몇 개에 대한 ID를 확인해보면 아래와 같다.
table.lookup(tf.constant([b'This movie was faaaaaantastic'.split()]))
# <tf.Tensor: [...], dtype=int64, numpy=array([[ 22, 12, 11, 10054]])>단어 this, movie, was는 룩업 테이블에 있으므로 이 단어들의 ID는 10,000보다 적다, 하지만 faaaaaantastic은 없기 때문에 10,000보다 크거나 같은 ID를 가진 oov 버킷 중 하나에 매핑된다.
이제 리뷰를 배치로 묶고 preprocess() 함수를 사용해 단어의 짧은 시퀀스로 바꾼다. 그다음 단어를 인코딩한다.
def encode_words(X_batch, y_batch):
return table.lookup(X_batch), y_batch
train_set = datasets['train'].batch(32).map(preprocess)
train_set = train_set.map(encode_words).prefetch(1)embed_size = 128
model = keras.models.Sequential([
keras.layers.Embedding(vocab_size + num_oov_buckets, embed_size, input_shape=[None]),
keras.layers.GRU(128, return_sequences=True),
keras.layers.GRU(128),
keras.layers.Dense(1, activation='sigmoid')
])
model.compile(loss='binary_crossentropy', optimizer='adam',
metrics=['accuracy'])
history = model.fit(train_set, epochs=5)16.2.1 마스킹
모델은 원래 데이터 그대로 패딩 토큰을 무시하도록 학습해야 한다. 패딩 토큰을 무시하도록 모델에게 알려주어 실제 의미가 있는 데이터에 집중할 수 있게 만들어야 한다. Embedding 층을 만들 때 mask_zero=True 매개변수를 추가하면 된다. 이러면 이어지는 모든 층에서 (ID가 0인) 패딩 토큰을 무시한다.
구체적으로 살펴보면 아래와 같다.
1. Embedding 층이 K.not_equal(inputs, 0) 와 같은 마스크 텐서를 만든다(K=keras.backend). 이 텐서는 입력과 크기가 같은 불리언 텐서다. 즉, ID가 0인 위치는 False이고 나머지는 True다. 이 마스크 텐서는 모델에 의해 이어지는 모든 층에 타임 스텝 차원이 유지되는 한 자동으로 전파된다.
2. 위 코드에선 2개의 GRU층이 자동으로 마스크 텐서를 받는다. 두 번째 GRU 층이 시퀀스를 반환하지 않으므로 Dense 층에는 마스크 텐서가 전달되지 않는다. 층마다 마스크 텐서를 다르게 다룰 수 있지만 일반적으로 마스킹된 타임 스텝을 무시한다.
예를 들어, 순환 층은 마스킹된 타임 스텝을 만나면 이전 타임 스텝의 출력을 단순히 복사한다. 만약 마스크가 출력에도 전파된다면 손실에도 적용될 수 있다. 하지만 시퀀스 모델에선 마스킹된 타임 스텝이 손실에 영향을 주지 않는다.
3. 마스크를 받는 모든 층은 마스킹을 지원해야 한다. 모든 순환 층은 물론 TimeDistributed 층과 몇 개의 다른 층도 포함된다. 마스킹을 지원하는 모든 층은 supports_masking 속성 값이 True다.
마스킹을 지원하는 사용자 정의 층을 구현하려면 call() 메서드에 mask 매개변수를 추가해야 한다. 또한 생성자에서 self.supports_masking=True 로 지정해야 한다. 사용자 정의 층이 Embedding 층으로 시작하지 않는다면 대신 keras.layers.Masking 층을 사용할 수 있다. 이 층은 마스크를 K.any(K.not_equal(inputs, 0), axis=-1) 로 세팅할 수 있다. 마지막 차원이 0으로 채워진 타임 스텝은 이어지는 모든 층에서 마스크 처리된다.
마스킹 층과 마스크 자동 전파는 Sequential 모델에 가장 잘 맞는다. Conv1D 층과 순환 층을 섞는 것과 같이 복잡한 모델에선 항상 작동하지 않는다. 이런 경우 함수형 API나 서브클래싱 API를 사용해 직접 마스크를 계산하여 다음 층에 전달해야 한다. 예를 들어 다음 모델은 이전 모델과 동일하지만 함수형 API를 사용해 직접 마스킹을 처리한다.
K = keras.backend
inputs = keras.layers.Input(shape=[None])
mask = keras.layers.Lambda(lambda inputs: K.not_equal(inputs, 0))(inputs)
z = keras.layers.Embedding(vocab_size + num_oov_buckets, embed_size)(inputs)
z = keras.layers.GRU(128, return_sequences=True)(z, mask=mask)
z = keras.layers.GRU(128)(z, mask=mask)
outputs = keras.layers.Dense(1, activation='sigmoid')(z)
model = keras.Model(inputs=[inputs], outputs=[outputs])16.2.2 사전훈련된 임베딩 재사용하기
텐서플로 허브 프로젝트는 사전훈련된 모델 컴포넌트(=모듈)를 모델에 추가하기 쉽게 만들어준다. 아래는 nnlm-en-dim50 문장 임베딩 모듈 버전 1을 감성 분석 모델에 사용해보는 것이다.
import tensorflow_hub as hub
model = keras.Sequential(p
hub.KerasLayer('https://tfhub.dev/google/tf2-preview/nnlm-en-dim50/1',
dtype=tf.string, input_shape=[], output_shape=[50]),
keras.layers.Dense(128, activation='relu'),
keras.layers.Dense(1, activation='sigmoid')
])
model.compile(loss='binary_crossentropy', optimizer='adam',
metrics=['accuracy'])위 허브 모듈의 이름은 문장 인코더(sentence encoder)이다. 문자열을 입력으로 받아 하나의 벡터로 인코딩한다(이 예제에선 50차원의 벡터). 기본적으로 hub.KerasLayer 층은 훈련되지 않지만 trainable=True 로 설정하여 작업에 맞게 미세 조정할 수 있다.
그다음 IMDb 리뷰 데이터셋을 다운로드한다. (배치 및 프리페치 제외) 따로 전처리 할 필요없이 바로 모델 훈련이 가능하다.
datasets, info = tfds.load('imdb_reviews', as_supervised=True, with_info=True)
train_size = info.splits['train'].num_examples
batch_size = 32
train_set = datasets['train'].batch(batch_size).prefetch(1)
history = model.fit(train_set, epochs=5)16.3 신경망 기계 번역을 위한 인코더-디코더 네트워크
영어 문장을 프랑스어로 번역하는 간단한 신경망 기계 번역 모델1을 살펴보자.
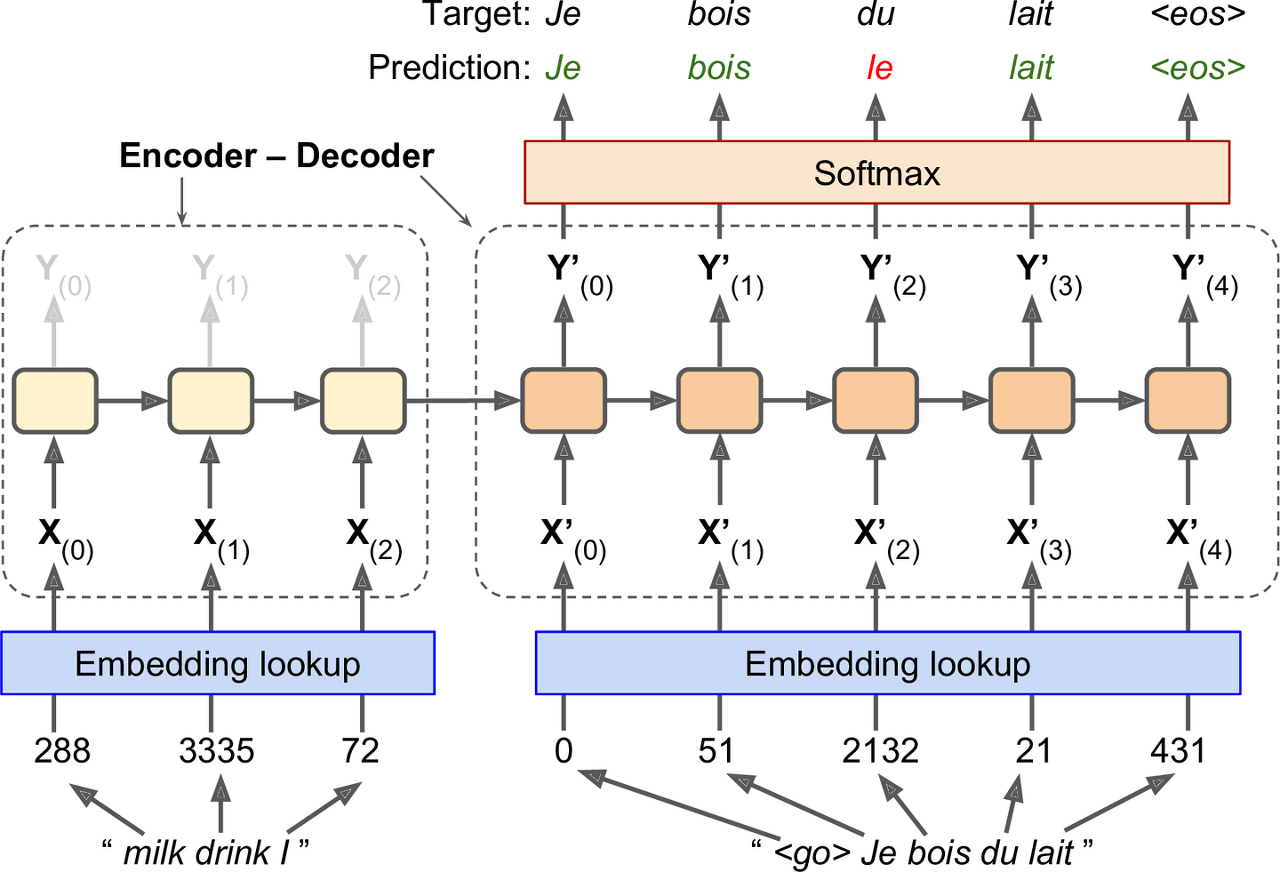
간략히 말하면 영어 문장을 인코더로 주입하면 디코더는 프랑스어 번역을 출력한다. 이때 프랑스어 번역은 한 스텝 뒤쳐져서 디코더의 입력으로도 사용된다. 다르게 말하면 디코더는 이전 스텝에서 출력된 단어를 입력으로 사용한다.
영어 문장은 인코더로 주입되기 전 거꾸로 뒤집힌다. 즉 영어 문장의 시작 부분을 인코더에 마지막으로 주입한다. 이 단어가 디코더가 번역할 첫 번째 단어이기 때문이다.
각 단어는 초기에 1차원으로 표현되어 있다(milk -> 288). 그다음 임베딩층이 단어 임베딩을 반환한다.
각 단계마다 디코더는 출력 어휘 사전(=프랑스어)에 있는 단어에 대한 점수를 출력한다. 그다음 소프트맥스 층이 이 점수를 확률로 바꾼다. 예를 들어, 첫 번째 스텝에서 단어 Je는 20% 확률을 갖고 Tu는 1% 확률을 갖는 식이다. 이는 일반적인 분류 작업과 매우 비슷하여 Char-RNN 모델과 같이 sparse_categorical_crossentropy 손실 함수를 사용해 훈련할 수 있다.
물론 추론 시에는 디코더에 주입할 타깃 문장이 없기 때문에 아래처럼 그냥 이전 스텝에서 디코더가 출력한 단어를 주입한다.

이 모델을 구현하려면 처리할 것이 조금 더 있다.
1. 문장을 비슷한 길이의 버킷으로 그룹핑하기(예: 한 버킷에 1개 ~ 6개 단어로 이루어진 문장을 담고, 또 다른 버킷에 7개 ~ 12개 단어로 이루어진 문장을 담기)
- 지금까지는 모든 입력 시퀀스의 길이가 동일하다고 가정했지만, 당연히 문장 길이는 다름
- 문장 길이가 많이 다르면 감성 분석에서 했던 것처럼 그냥 잘라낼 수는 없음
- 버킷에 담긴 문장이 모두 동일한 길이가 되도록 패딩 추가
2. EOS 토큰 이후 출력은 모두 무시
- 해당 토큰들은 손실에 영향을 미치지 않음
3. 샘플링 소프트맥스 사용하기(타깃 단어에 대한 로짓과 타깃이 아닌 단어 중 무작위로 샘플링한 단어의 로짓만 고려)
- 출력 어휘 사전이 방대할 경우 모든 단어의 확률을 출력하려면 매우 느려짐(연산 비용 高)
- 샘플링 소프트맥스는 타깃을 알고 있어야 하므로 추론 시에는 사용 불가능
텐서플로 애드온(Addon) 프로젝트는 여러 가지 시퀀스-투-시퀀스 도구를 가지고 있어 제품 수준의 인코더-디코더를 손쉽게 만들 수 있다.
import tensorflow_addons as tfa
encoder_inputs = keras.layers.Input(shape=[None], dtype=np.int32)
decoder_inputs = keras.layers.Input(shape=[None], dtype=np.int32)
sequence_lengths = keras.layers.Input(shape=[], dtype=np.int32)
embeddings = keras.layers.Embedding(vocab_size, embed_size)
encoder_embeddings = embeddings(encoder_inputs)
decoder_embeddings = embeddings(decoder_inputs)
encoder = keras.layers.LSTM(512, return_state=True)
encoder_outputs, state_h, state_c = encoder(encoder_embeddings) # LSTM이므로 은닉 상태 2개(단기, 장기)
encoder_state = [state_h, state_c]
sampler = tfa.seq2seq.sampler.TrainingSampler()
decoder_cell = keras.layers.LSTMCell(512)
output_layer = keras.layers.Dense(vocab_size)
decoder = tfa.seq2seq.basic_decoder.BasicDecoder(decoder_cell, sampler,
output_layer=output_layer)
final_outputs, final_state, final_sequence_lengths = decoder(
decoder_embeddings, initial_state=encoder_state,
sequence_length=sequence_lengths)
Y_proba = tf.nn.softmax(final_outputs.rnn_output)
model = keras.Model(inputs=[encoder_inputs, decoder_inputs, sequence_lengths],
outputs=[Y_proba])TrainingSampler
- 각 스텝에서 디코더에게 이전 스텝의 출력이 무엇인지 알려주는 역할
- 추론 시에는 실제로 출력되는 토큰의 임베딩이 됨 <-> 훈련 시에는 이전 타깃 토큰의 임베딩이 됨
16.3.1 양방향 RNN
각 타임 스텝에서 일반적인 순환 층은 과거와 현재의 입력만 보고 출력을 생성한다. 이는 인과적(casual), 즉 미래를 볼 수 없다는 뜻이다. 신경망 기계 번역 같은 여러 종류의 NLP 작업은 주어진 단어를 인코딩하기 전에 다음 단어를 미리 보는 것이 좋다.
이를 위해 동일한 입력에 대해 두 개의 순환 층을 실행한다. 하나는 왼쪽에서 오른쪽으로 단어를 읽고, 다른 하나는 오른쪽에서 왼쪽으로 읽는다. 그다음 일반적으로 타임 스텝마다 이 두 출력을 연결한다. 이를 양방향 순환 층(bidirectional recurrent layer)이라고 한다.
keras.layers.Bidirectional(keras.layers.GRU(10, return_sequences=True))16.3.2 빔 검색
인코더-디코더 모델을 훈련할 땐 실수가 있더라도 뒤로 돌아가 고칠 수 없어 가능한 최선을 다해 문장을 완성해야 한다. 그렇다고 스텝마다 무조건 가장 가능성 있는 단어를 출력해서는 최적의 번역을 만들지 못한다.
모델이 앞선 실수를 고칠 수 있는 방법 중 하나는 빔 검색(beam search)이다. k개의 가능성 있는 문장의 리스트를 유지하고 디코더 단계마다 이 문장의 단어를 하나씩 생성하여 가능성 있는 k개의 문장을 만든다. 파라미터 k를 빔 너비(beam width)라고 한다.
예를 들어, 빔 너비 3의 빔 검색으로 'Comment vas-tu?'를 번역한다고 하자. 첫 번째 디코더 스텝에서 모델이 가능한 모든 단어에 대한 추정 확률을 출력할 것이다. 최상위 세 개 단어를 How(75%), What(3%), You(1%)라고 가정한다면 이들이 현재 리스트다.
그다음 세 개 모델로 복사하여 각 문장의 다음 단어를 찾는다. 각 모델은 어휘 사전에 있는 단어에 해당하는 추정 확률을 출력한다. 첫 번째 모델은 How에 이어질 단어를 찾으며 will에 대해 36% 확률, are은 32%, do는 16% 확률을 출력한다. 실제로 이 값은 How로 시작하는 문장이 주어졌을 때의 조건부 확률이다.
두 번째 모델은 What 문장을 이어나가고, 단어 are에 대해 50% 조건부확률을 출력하는 식이다. 어휘 사전에 10,000개가 있다고 가정하면 각 모델은 10,000개의 확률을 출력할 것이다.
그다음 이 모델이 두 개의 단어로 이루어진 30,000개의 문장(3 x 10,000)에 대해 확률을 계산한다. 이를 위해 완성된 문장의 추정된 확률에 각 단어의 추정된 조건부 확률을 곱한다. How의 추정 확률이 75%고, 단어 will에 대한 추정된 조건부 확률이 36%라면 How will 문장의 추정 확률은 75% x 36% = 27%이다. 두 단어로 이루어진 문장 30,000개의 확률을 계산한 후 최상위 3개만 추린다. 이들은 모두 How 단어로 시작하며 How will(27%), How are(24%), How do(12%)와 같다.
그다음 동일한 과정을 반복한다. How are you(10%), How do you(8%), How will you(2%), 다음 단계에서 How do you do(7%), How are you <eos>(6%), How are you doing(3%)을 얻을 수 있다. 여기서 How will은 제외되었고 남은 번역 세 개는 모두 납득할 만하다.
아래는 탠서플로 애드온을 사용하여 빔 검색을 구현한 것이다.
beam_width = 10
decoder = tfa.seq2seq.beam_search_decoder.BeamSearchDecoder(
cell=decoder_cell, beam_width=beam_width, output_layer=output_layer)
decoder_initial_state = tfa.seq2seq.beam_search.tile_batch(
encoder_state, multiplier=beam_width)
outputs, _, _ = decoder(
embedding_decoder, start_tokens=start_tokens, end_token=end_token,
initial_state=decoder_initial_state)16.4 어텐션 메커니즘
드미트리 바흐다나우(Dzmitry Bahdanau) 등은 2014년에 발표한 논문2에서 각 타임 스텝에서 적절한 단어에 디코더가 초점을 맞추도록 하는 기술을 소개했다.
이는 입력 단어에서 번역까지 경로를 훨씬 짧게 만들어 RNN의 단기 기억의 제한성에 훨씬 적은 영향을 받게 된다. 아래 그림을 보면 인코더의 마지막 은닉 상태만 디코더에 보내는 것이 아니라 인코더의 모든 출력을 디코더로 전송한다. 각 타임 스텝에서 디코더의 메모리 셀은 이런 모든 인코더 출력의 가중치 합을 계산하고, 주의를 집중할 단어를 결정한다.
α(t,i) 가중치는 t번째 디코더 타임 스텝에서 i번째 인코더 출력의 가중치다. 예를 들어 가중치 α(3,2)는 가중치 α(3,0)과 α(3,1)보다 훨씬 크다면 적어도 이 타임 스텝에서 디코더는 다른 단어보다 두 번째 단어에 훨씬 많은 주의를 기울일 것이다.
그렇다면 α(t,i) 가중치는 어디에서 오는 것일까? 이는 정렬 모델(alignment model, 또는 attention layer)이라 부르는 작은 신경망에 의해 생성된다. TimeDistributed 클래스를 적용한 Dense 층으로 시작한다.
이 층은 하나의 뉴런으로 구성되고 인코더의 모든 출력을 입력으로 받아 디코더의 이전 은닉 상태를 연결한다. 이 층은 각 인코더 출력에 대한 점수(또는 에너지)를 출력한다. 이 점수는 각 출력이 디코더의 은닉 상태와 얼마나 잘 맞는지 측정하는 것이다. 마지막으로 모든 점수가 소프트맥스 층을 통과해 각 인코더 출력에 대한 최종 가중치를 얻는다.
위와 같은 어텐션 메커니즘을 바흐다나우 어텐션(Bahdanau attention)이라 부르고, 인코더 출력과 디코더 이전 은닉 상태를 연결하므로 연결 어텐션(concatenative attention, 또는 덧셈 어텐션(additive attention))이라고도 부른다.
또 다른 어텐션 메커니즘은 민-탕 루옹(Minh-Thang Luong) 등이 2015년 논문3에 제안한 것이다. 이 메커니즘의 목적은 인코더의 출력 하나와 디코더의 이전 은닉 상태 사이의 유사도를 측정하는 것이므로 간단히 두 벡터 사이의 점곱을 제안했다.
이렇게 하려면 두 벡터는 동일한 차원을 가져야 한다. 이를 루옹 어텐션(Luong attention) 또는 곱셈 어텐션(multiplicative attention)이라 부른다. 또 다른 간소화된 버전은 이전 타임 스텝이 아니라 현재 타임 스텝에서 디코더의 은닉 상태를 사용하는 것이다(h(t−1)이 아니라 h(t)). 그다음 어텐션 메커니즘의 출력(~h(t))을 사용하여 (디코더의 현재 은닉 상태를 계산하지 않고) 바로 디코더의 예측을 계산한다.
또 하나의 변종은 인코더 출력이 점곱 계산 전에 먼저 선형 변환(즉, 편향 없는 TimeDistributed가 적용된 Dense 층)을 통과하는 것이다. 이를 '일반' 점곱 방법이라 부른다. 참고로 점곱 변종이 연결 어텐션보다 더 높은 성능이 나오기 때문에 이젠 연결 어텐션이 많이 사용되지 않는다.
~h(t)=∑iα(t,i)y(i)
여기에서
α(t,i)=exp(e(t,i))∑i′exp(e(t,i′))
e(t,i)=hT(t)y(i) <- 점곱
=hT(t)Wy(i) <- 일반 점곱
=vTtanh(W[h(t);y(t)]) <- 연결(v는 스케일 재조정 파라미터 벡터)
다음은 텐서플로 애드온을 사용해 인코더-디코더 모델에 루옹 어텐션을 추가하는 방법이다.
attention_mechanism = tfa.seq2seq.attention_wrapper.LuongAttention(
units, encoder_state, memory_sequence_length=encoder_sequence_length)
attention_decoder_cell = tfa.seq2seq.attention_wrapper.AttentionWrapper(
decoder_cell, attention_mechanism, attention_layer_size=n_units)16.4.2 트랜스포머 구조: 어텐션이 필요한 전부다
2017년 구글 연구팀은 한 논문4에서 '어텐션이 필요한 전부다' 라고 제안했다. 트랜스포머(Transformer)란 구조는 순환 층이나 합성곱 층을 전혀 사용하지 않고 어텐션 메커니즘만 사용해 NMT(Neural Machine Translation) 문제에서 최고 수준 성능을 크게 향상했다. 추가로 이 구조를 훨씬 빠르게 훈련할 수 있고 병렬화하기 쉽다는 장점이 있다.
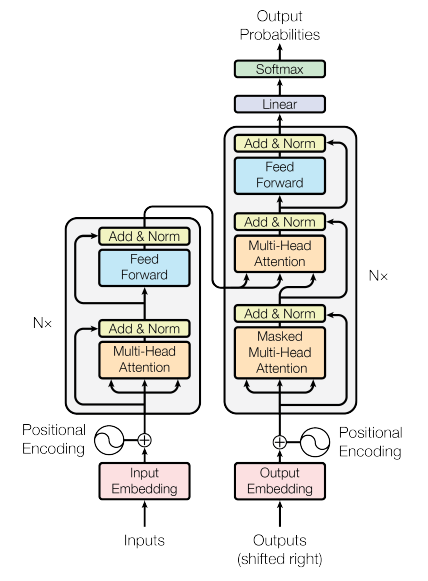
왼쪽 부분: 인코더
- 단어 ID의 시퀀스로 표현된 문장의 배치를 입력으로 받음(입력 크기는 [배치 크기, 입력 문장 최대 길이])
- 인코더는 각 단어를 512차원의 표현으로 인코딩(출력 크기는 [배치 크기, 입력 문장 최대 길이, 512])
- 인코더 윗부분은 N번 반복되어 쌓아 올림
오른쪽 부분: 디코더
- 훈련하는 동안 타깃 문장을 입력으로 받음
ㄴ 오른쪽으로 한 타임 스텝 이동(시작 부분에 SOS 토큰 추가)
- 인코더 출력을 받음
- 디코더 윗부분도 N번 반복되어 쌓아 올림
- 인코더의 최종 출력이 N번의 디코더에 모두 주입
- 타임 스텝마다 가능한 다음 단어에 대한 확률을 출력(출력 크기는 [배치 크기, 출력 문장의 최대 길이, 어휘 사전 길이])
구체적 특징
- 모든 층은 타임 스텝에 독립적(time-distributed)으로, 각 단어는 다른 모든 단어에 대해 독립적으로 처리
- 인코더 멀티-헤드 어텐션(masked multi-head attention) 층은 관련이 많은 단어에 더 많은 주의를 기울이며 각 단어와 동일한 문장에 있는 다른 단어의 관계를 인코딩
ㄴ 예를 들어, 'They welcomed the Queen of the United Kingdom'에 있는 단어 Queen에 대해 이 층의 출력은 문장에 있는 모든 단어에 의존적
ㄴ 하지만 They나 welcomed보단 United와 Kingdom에 더 주의를 기울일 것이고, 이를 셀프-어텐션(self-attention)이라 부름
- 디코더의 마스크드 멀티-헤드 어텐션 층도 동일한 작업을 수행하지만 각 단어는 이전에 등장한 단어에만 주의를 기울일 수 있음
- 마지막 디코더 위쪽 멀티-헤드 어텐션 층은 디코더가 입력 문장에 있는 단어에 주의를 기울이는 작업 수행
- 위치 인코딩(positional encoding)은 문장에 있는 단어의 위치를 나타내는 단순한 밀집 벡터
ㄴ n번째 위치 인코딩이 각 문장에 있는 n번째 단어의 단어 임베딩에 더해짐
ㄴ 이를 통해 모델이 각 단어의 위치를 알 수 있는데, 멀티-헤드 어텐션 층이 단어 사이 관계만 보고 단어의 순서나 위치를 고려하지 않기 때문에 필요
위치 인코딩
위치 인코딩은 문장 안에 있는 단어의 위치를 인코딩한 밀집 벡터다. 단순히 i번째 위치 인코딩이 문장에 있는 i번째 단어의 단어 임베딩에 더해진다. 논문에서는 여러 가지 주기의 사인과 코사인 함수로 정의한 고정된 위치 인코딩을 선호했다.
Pp,2i=sin(p/10002i/d)
Pp,2i+1=cos(p/100002i/d)
위치마다 고유한 위치 인코딩이 만들어지기 때문에 위치 인코딩을 단어 임베딩에 더하면 모델이 문장에 있는 단어의 절대 위치를 알 수 있다.
텐서플로는 PositionalEmbedding과 같은 층이 없지만 만드는 것이 어렵지 않다. 효율적인 이유로 생성자에서 위치 인코딩 행렬을 미리 계산한다(문장 최대 길이 max_steps와 각 단어를 표현할 차원수 max_dims를 알아야 함). 그다음 call() 메서드에서 인코딩 행렬을 입력의 크기로 잘라 입력에 더한다.
class PositionalEncoding(keras.layers.layer):
def __init__(self, max_steps, max_dims, dtype=tf.float32, **kwargs):
super().__init__(dtype=dtype, **kwargs)
if max_dims % 2 == 1:
max_dims += 1 # max_dims는 짝수여야 함
p, i = np.meshgrid(np.arange(max_steps), np.arange(max_dims // 2))
pos_emb = np.empty((1, max_steps, max_dims))
pos_emb[0, :, ::2] = np.sin(p / 10000**(2 * i / max_dims)).T
pos_emb[0, :, 1::2] = np.cos(p / 10000**(2 * i / max_dims)).T
self.positional_embedding = tf.constant(pos_emb.astype(self.dtype))
def call(self, inputs):
shape = tf.shape(inputs)
return inputs + self.positional_embedding[:, :shape[-2], :shape[-1]]아래는 트랜스포머의 첫 번째 층이다.
embed_size = 512
max_steps = 500
vocab_size = 10000
encoder_inputs = keras.layers.Input(shape=[None], dtype=np.int32)
decoder_inputs = keras.layers.Input(shape[None], dtype=np.int32)
embeddings = keras.layers.Embedding(vocab_size, embed_size)
encoder_embeddings = embeddings(encoder_inputs)
decoder_embeddings = embeddings(decoder_inputs)
positional_encoding = PositionalEncoding(max_steps, max_dims=embed_size)
encoder_in = positional_encoding(encoder_embeddings)
decoder_in = positional_encoding(decoder_embeddings)멀티-헤드 어텐션
멀티-헤드 어텐션 층의 기본은 스케일드 점-곱 어텐션(scaled dot-product attention) 층이다. 모델은 ('주어'나 '동사' 같은) 키를 표현하기 위한 구분되는 토큰을 갖지 않으며, 대신 (훈련하는 동안 학습된) 벡터 표현으로 이 개념을 갖는다. 따라서 룩업에 사용할 키(=쿼리)는 딕셔너리에 있는 키와 완벽하게 매칭되지 않는다.
한 가지 방법은 쿼리와 딕셔너리에 있는 각 키 사이의 유사도를 계산하는 것이다. 이후 소프트맥스 함수를 사용해 유사도 점수를 합해 1이 되는 가중치로 바꾼다. 동사를 표현하는 키가 쿼리와 가장 비슷하다면 이 키의 가중치는 1에 가까울 것이다. 그다음 모델이 키에 해당하는 값의 가중치 합을 계산할 수 있다. 따라서 동사의 키 가중치가 1에 가까우면 이 가중치 합은 단어 played의 표현에 매우 가깝게 될 것이다.
간단히 요약하면 이런 과정 전체를 미분가능한 딕셔너리 룩업으로 생각할 수 있다. 트랜스포머에서 사용하는 유사도 측정 방법은 루옹 어텐션과 같은 점곱이다.
Attention(Q,K,V) = softmax(QKT√dkeys) V
- Q: 행마다 쿼리(query) 하나를 담은 행렬이며 크기는 [nqueries,dkeys]이다. 여기서 nqueries는 쿼리 개수, dkeys는 쿼리와 키의 차원 개수다.
- K: 행마다 키(key) 하나를 담은 행렬이며 크기는 [nkeys,dkeys]이다. 여기서 nkeys는 키와 값의 개수다.
- V: 행마다 값(value) 하나를 담은 행렬이며 크기는 [nkeys,dvalues]이다. 여기서 dvalues는 값의 차원이다.
- QKT: 크기는 [nqueries,nkeys]이며, 쿼리/키 쌍마다 하나의 유사도 점수를 담고 있다. 소프트맥스 함수의 출력도 동일한 크기이지만 모든 행은 합이 1이다. 최종 출력의 크기는 [nqueries,dvalues]이다. 하나의 행은 하나의 쿼리에 해당하고, 각 행은 쿼리 결과(값의 가중치 합)를 나타낸다.
- 스케일링 인자는 소프트맥스 함수가 포화되어 그레이디언트가 너무 작아지지 않도록 유사도 점수를 낮춘다.
- 소프트맥스 함수를 계산하기 전 유사도 점수에 아주 큰 음수를 더해 일부 키/값 쌍을 제외하도록 마스킹처리 할 수 있다. 이것이 마스크된 멀티-헤드 어텐션에서 사용하는 방법이다.
인코더에서 이 식이 배치에 있는 모든 입력 문장에 적용된다. Q,K,V는 모두 입력 문장에 있는 단어 목록과 동일하다(따라서 문장에 있는 각 단어는 자기자신을 포함해 같은 문장의 모든 단어와 비교될 것이다). 비슷하게 디코더의 마스킹된 어텐션 층에서 이 식이 배치에 있는 모든 타깃 문장에 적용된다. Q,K,V는 타깃 문장에 있는 단어의 목록과 동일하다.
하지만 이번에는 뒤에 오는 단어를 비교하지 않기 위해 마스킹을 사용한다. 추론할 때 디코더는 미래 단어가 아니라 이미 출력된 단어만 참조할 수 있기 때문이다. 디코더의 위쪽 어텐션 층에서 키 K와 값 V는 단순히 인코더가 생성한 단어 인코딩의 리스트다. 쿼리 Q는 디코더가 생성한 단어 인코딩의 리스트다.
멀티-헤드 어텐션이 아니라 스케일드 점-곱 어텐션이라는 것과 스킵 연결, 층 정규화, 피드포워드 모듈을 무시한다면 트랜스포머 모델의 나머지 부분은 아래와 같이 구현할 수 있다.
Z = encoder_in
for N in range(6):
Z = keras.layers.Attention(use_scale=True)([Z, Z])
encoder_outputs = Z
Z = decoder_in
for N in range(6):
Z = keras.layers.Attention(use_scale=True, casual=True)([Z, Z])
Z = keras.layers.Attention(use_scale=True)([Z, encoder_outputs])
outputs = keras.layers.TimeDistributed(
keras.layers.Dense(vocab_size, activation='softmax'))(Z)use_scale=True 로 지정하면 파라미터가 추가되어 유사도 점수의 스케일을 적절히 낮추는 방법을 배운다.
casual=True 로 지정하면 각 출력 토큰은 미래 토큰이 아니라 이전 출력 토큰에만 주의를 기울인다.
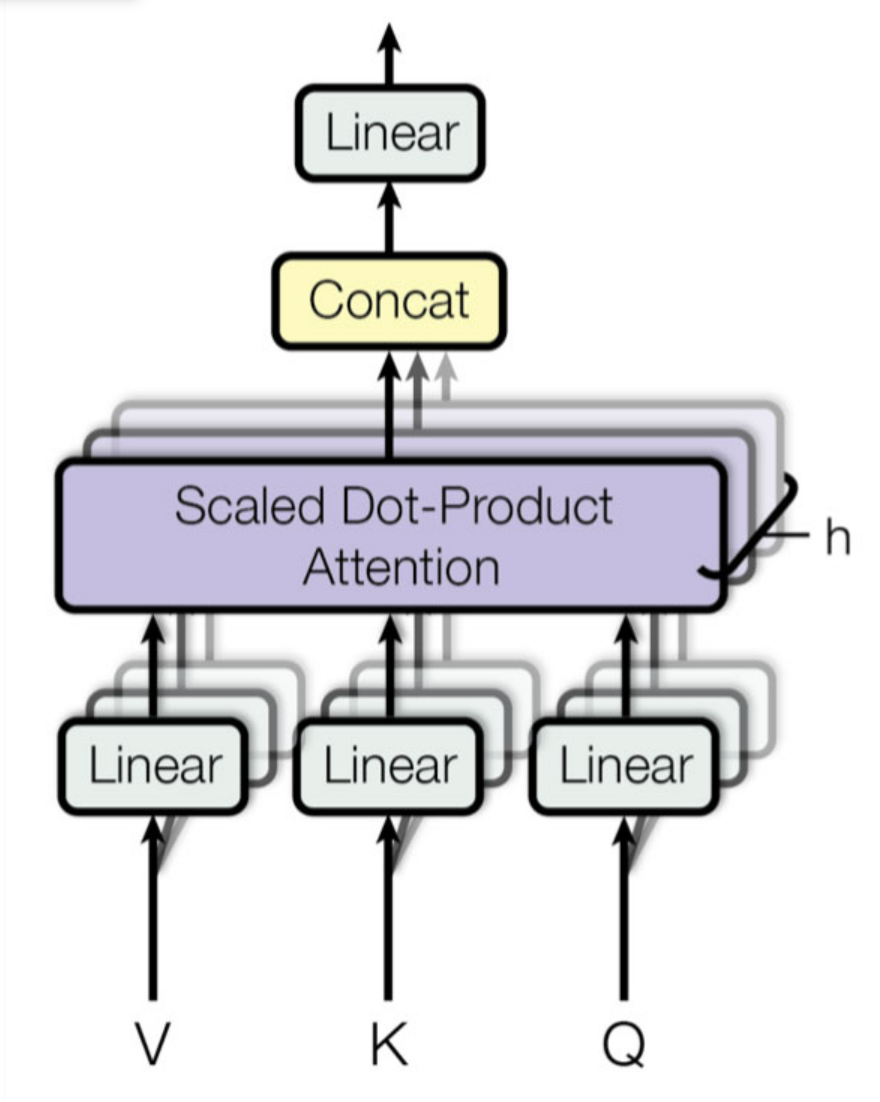
멀티-헤드 어텐션은 스케일드 점-곱 어텐션 층의 묶음이다. 각 층은 값, 키, 쿼리의 선형 변환이 선행된다. 출력은 단순히 모두 연결되어 마지막 선형 변환을 통과한다.
단어 played를 생각해보면 인코더가 동사라고 인코딩할 수 있고, 텍스트 위치도 표현하고, 과거형이란 특징도 포함할 수 있다. 즉, 단어 표현은 단어에 있는 많은 특징을 인코딩한다. 하나의 스케일드 점-곱 어텐션 층만 사용한다면 한번에 이런 특징을 모두 쿼리할 수밖에 없다. 이것이 멀티-헤드 어텐션 층이 값, 키, 쿼리의 여러 가지 선형 변환을 적용하는 이유다. 이를 통해 모델이 단어 표현을 여러 부분 공간(subspace)으로 다양하게 투영할 수 있다.
이 부분 공간은 단어의 일부 특징에 주목한다. 선형 층 중 하나가 단어 표현을 이 단어가 동사라는 정보만 남는 하나의 공간으로 투영한다. 또 다른 선형 층은 과거형이라는 사실만 추출한다. 이렇게 스케일드 점-곱 어텐션 층이 룩업 단계를 구현하고 마지막으로 모든 결과를 연결하여 원본 공간으로 다시 투영한다.
'문돌이 존버 > 데이터 분석' 카테고리의 다른 글
| 핸즈온 머신러닝 2 복습하기(챕터 17: 오토인코더와 GAN을 사용한 표현 학습과 생성적 학습) (1) | 2024.01.05 |
|---|---|
| 핸즈온 머신러닝 2 복습하기(챕터 15: RNN과 CNN을 사용해 시퀀스 처리하기) (1) | 2023.10.05 |
| 핸즈온 머신러닝 2 복습하기(챕터 14: 합성곱 신경망을 사용한 컴퓨터 비전) (0) | 2022.05.02 |
| 핸즈온 머신러닝 2 복습하기(챕터 11: 심층 신경망 훈련하기) (0) | 2022.01.01 |
| 버트(BERT) 개념 간단히 이해하기 (2) | 2021.11.17 |



