14.1 시각 피질 구조
합성곱 신경망은 시각 피질 안의 많은 뉴런이 작은 국부 수용장(local receptive field)에서 아이디어를 얻었다. 뉴런들이 시야의 일부 범위 안에 있는 시각 자극에만 반응한다는 것이다.
14.2 합성곱 층
CNN의 가장 중요한 구성 요소는 합성곱 층(convolutional layer)이다. 첫 번째 합성곱 층의 뉴런은 입력 이미지의 모든 픽셀에 연결되는 것이 아니라 합성곱 층 뉴런의 수용장 안에 있는 픽셀에만 연결된다. 두 번째 합성곱 층에 있는 각 뉴런은 첫 번째 층의 작은 사각 영역 안에 위치한 뉴런에 연결된다. 합성곱 신경망에선 해당 수용장을 필터(filter)라고 부른다. CNN에서 필터와 커널(kernel)은 혼용되어 쓰이는데, 엄격히 구분하자면 필터는 여러 개의 커널로 구성되어 있다. 뒤에서 살펴볼 채널 수가 곧 커널 수가 되고, 이것들이 모여 하나의 필터를 구성하는 것이다.
스트라이드(Stride)는 입력 데이터(원본 이미지 or 특성 맵)에 필터를 적용할 때 sliding window가 이동하는 간격을 의미한다. 즉 필터를 움직일 때 몇 칸만큼의 간격을 두고 이동(shift)해서 입력 데이터의 특성을 추출할 것인지 정하는 것이다.

위의 예제를 보면 스트라이드가 1(기본값)일 때는 한 칸씩 움직이는 것을 알 수 있다. 반면 스트라이드 2의 경우 두 칸씩 이동한다. 이렇게 하면 공간적인 특성을 손실할 가능성이 높아지지만, 모델의 계산 복잡도를 크게 낮추고 연산 속도를 향상시키는 효과가 있다.
패딩(padding)은 합성곱 연산 수행 시 출력 특성 맵(feature map)이 입력 특성 맵 대비 계속 작아지는 것을 막기 위한 기법이다. 필터 적용 전에 보존하고자 하는 특성 맵 크기만큼 입력 특성 맵의 상하좌우 끝에 0값을 채워(=zero padding) 입력 특성 맵 사이즈를 늘리면 된다.
위 그림을 보면 원본 입력 특성 맵 크기가 6 x 6인데, 상하좌우에 0을 각각 채움으로써 8 x 8 크기로 만들었다. 커널 크기는 3 x 3으로 패딩을 하지 않았다면 출력 크기가 4 x 4로 되었겠지만 패딩을 함으로써 원본 특성 맵 크기를 유지했다.
패딩을 하면 모서리 주변의 합성곱 연산 횟수가 증가되어 모서리 주변 특성들의 특징을 보다 강화할 수 있다는 장점이 있다. 물론 모서리 주변값이 0이므로 노이즈가 약간 증가되기도 하지만 큰 영향은 없다.
(여기서 잠깐!)
1. 입력 특성 맵, 필터 크기, 패딩, 스트라이드를 알면 출력 특성 맵의 크기를 계산할 수 있다.
O=I−F+2PS+1
I: 입력 특성 맵 크기
F: 필터 크기
P: 패딩(P=1: 상하좌우에 1개씩)
S: 스트라이드
위의 수식은 채널 수를 고려하지 않음
2. 출력 특성 맵의 채널 수는 필터 개수로 결정된다.
- 필터는 여러 개의 커널(=채널)로 이루어져 있고, 이런 필터가 몇 개 있는지가 곧 출력 특성 맵의 채널 수를 결정
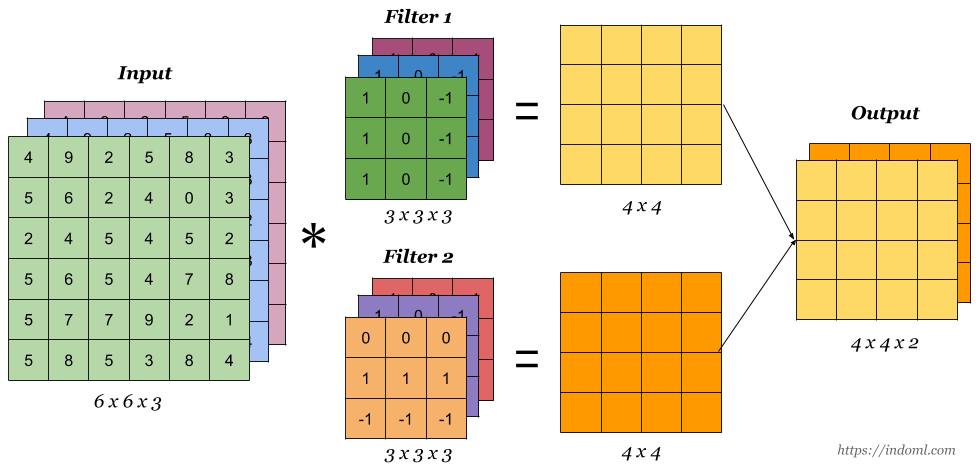
위 수식에서 보듯이 커널 크기가 짝수이면 소수점으로 계산되어 나오기 때문에 보통 홀수(3 x 3, 5 x 5 등)로 커널 크기를 설정한다. 최근에는 대부분 3 x 3 커널을 사용한다고 한다. 만약 소수점이 나오면 소수점은 버려지게 된다. 필터값은 우리가 수동으로 정의할 필요 없이 훈련하는 동안 합성곱 층이 자동으로 최적의 값을 찾게 된다.
위 그림과 같이 출력 특성 맵은 여러 채널(=필터 개수)을 가질 수 있다. 이는 곧 하나의 합성곱 층이 입력에 여러 필터를 동시에 적용하여 입력에 있는 여러 특성을 감지할 수 있다는 것을 의미한다. 각 특성 맵의 픽셀은 하나의 뉴런에 해당하는데, 하나의 특성 맵 안에선 모든 뉴런이 같은 파라미터(가중치, 편향)를 공유하지만 다른 특성 맵에 있는 뉴런은 다른 파라미터를 사용한다. 한 특성 맵에 있는 모든 뉴런이 같은 파라미터를 공유한다는 사실은 모델의 전체 파라미터 수를 급격하게 줄여준다는 장점이 있다.
합성곱 층에 있는 뉴런의 출력을 계산하는 수식은 아래와 같다. 수식은 복잡하지만 합성곱 층 계산 과정만 이해해도 충분하다.
zi,j,k=bk+∑fh−1u=0∑fw−1v=0∑f′n−1k′=0xi′,j′,k′×wu,v,k′,k
,where i′:i×sh+u
j′:j×sw+v
zi,j,k: 합성곱 층(l 층)의 k 특성 맵에서 i행, j열에 위치한 뉴런의 출력
sh, sw: 수직과 수평 스트라이드
fh, fw: 필터의 높이와 너비
fn′: 이전 층(l - 1층)에 있는 특성 맵 수
xi′,j′,k′: l-1 층의 i′행, j′열, k′ 특성 맵(혹은 l-1층이 입력층이면 k′ 채널)에 있는 뉴런의 출력
bk는 (l 레이어에 있는) k 특성 맵의 편향, 이를 k 특성 맵의 전체 밝기를 조정하는 다이얼로 생각할 수 있음
wu,v,k′,k: l층의 k 특성 맵에 있는 모든 뉴런과 (뉴런의 필터에 연관된) u행, v열, k′ 특성 맵에 위치한 입력 사이의 연결 가중치
텐서플로로 합성곱 층은 다음과 같이 구현한다.
conv = keras.layers.Conv2D(filters=32, kernel_size=3, strides=1,
padding='same', activation='relu')이 코드는 3 x 3 크기의 32개 필터, (수평과 수직 방향) 스트라이드 1을 사용한다. padding='same' 이라고 되어 있는데, 이는 패딩을 추가하여 출력 특성 맵이 입력 특성 맵의 크기를 그대로 유지하게 만드는 것이다(padding='valid' 라고 하면 패딩을 추가하지 않음).
14.3 풀링 층
풀링 층의 목적은 계산량과 메모리 사용량, (결과적으로 과대적합의 위험을 줄여주는) 파라미터 수를 줄이기 위해 입력 이미지의 부표본(subsample)을 만드는 것이다. 풀링 뉴런은 가중치가 없이 최대나 평균과 같은 합산 함수를 사용해 입력값을 더하는 것이 전부다.
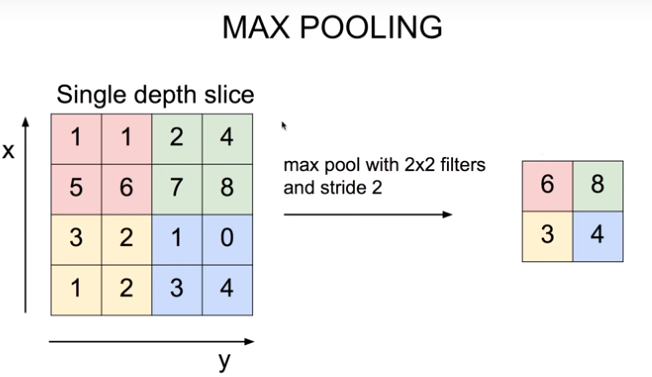
위 그림은 합성곱 층을 통해 출력된 특성 맵에 2 x 2 크기의 풀링 층(스트라이드 2)을 적용한 결과다. 아주 널리 사용되는 최대 풀링 층(max pooling layer)으로 말 그대로 해당 영역에서 가장 큰 값을 추출하는 것이다. 최대 풀링은 작은 변화에도 일정 수준의 불변성(invariance)을 만들어준다. 이와 같은 불변성은 분류 작업처럼 예측이 이런 작은 부분에서 영향을 받지 않는 경우 유용할 수 있다.
하지만 최대 풀링은 파괴적이기 때문에 2 x 2 필터와 스트라이드 2를 사용해도 출력은 양방향으로 절반이 줄어들어 입력값의 75%를 잃게 된다. 시맨틱 분할의 경우 불변성이 필요하지 않고 등변성(equivariance)이 목표가 되므로 입력의 작은 변화가 출력에서 그에 상응되는 작은 변화로 이어져야 한다.
14.3.1 텐서플로 구현
텐서플로로 최대 풀링 층을 구현하는 방법은 아래와 같다.
max_pool = keras.layers.MaxPool2D(pool_size=2) # 기본적으로 padding='valid'평균 풀링 층(average pooling layer)은 AvgPool2D 를 사용한다. 최댓값이 아닌 평균을 계산하는 것이고, 일반적으로 최대 풀링 층의 성능이 더 좋아 대부분 최대 풀링 층을 사용한다.
흔하지는 않지만 최대 풀링과 평균 풀링은 공간 차원이 아니라 깊이 차원으로 수행될 수 있다. 이를 통해 CNN이 다양한 특성에 대한 불변성을 학습할 수 있다. 아래 그림처럼 입력 이미지가 회전된다 하더라도 깊이방향(depthwise) 최대 풀링 층은 그와 상관없이 동일 출력을 만든다(두께, 밝기, 왜곡, 색상 등도 가능).
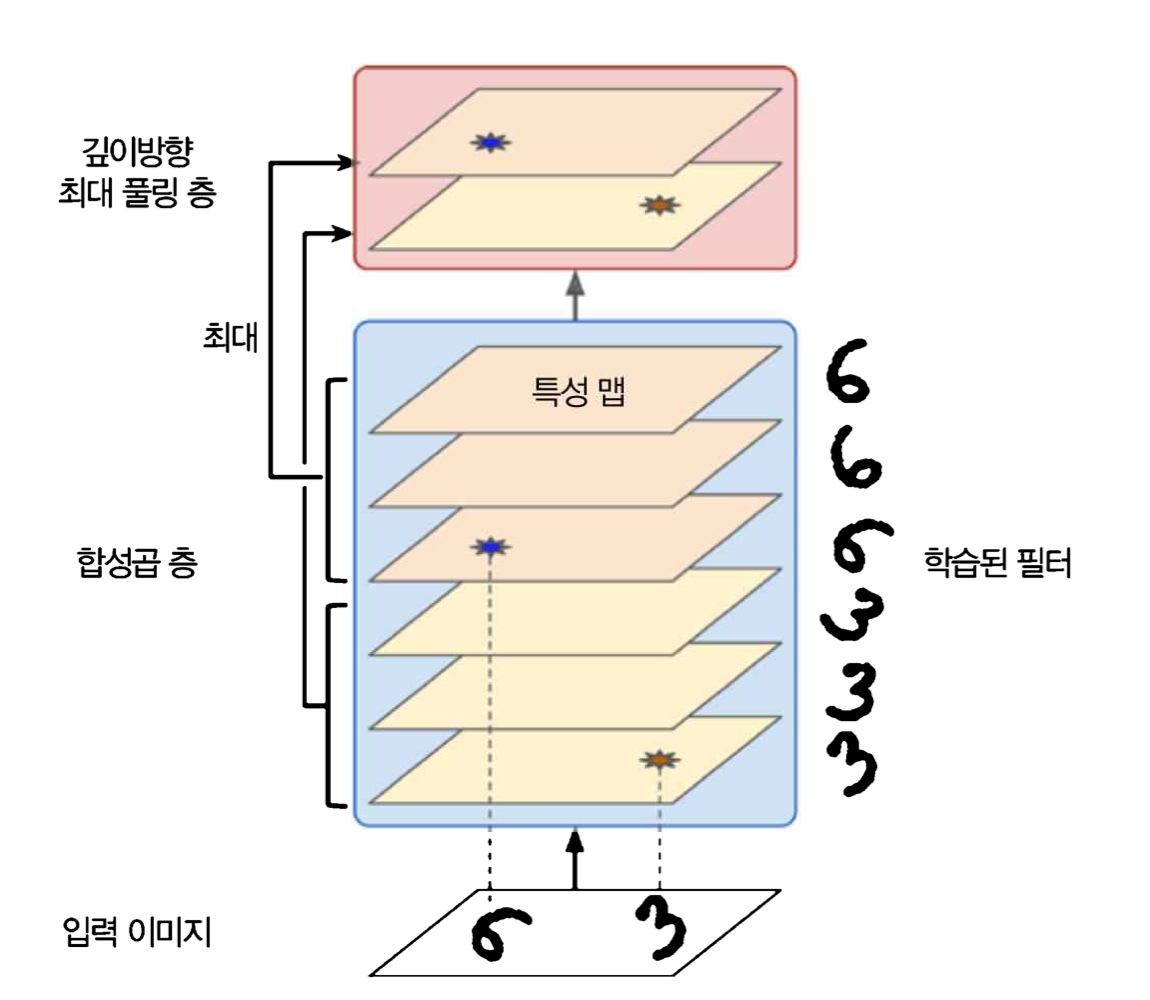
케라스에선 깊이방향 풀링 층을 제공하지 않지만 텐서플로 저수준 딥러닝 API를 사용하면 된다. tf.nn.max_pool() 함수를 사용하고 커널 크기와 스트라이드를 4개의 원소를 가진 튜플로 지정한다. 첫 번째 세 값은 1이어야 하는데, 이는 배치, 높이, 너비 차원을 따라 커널 크기와 스트라이드가 1이란 뜻이다. 마지막 값은 깊이 차원을 따라 원하는 커널 크기와 스트라이드를 가리킨다(입력 깊이를 나누었을 때 떨어지는 값이어야 함, 이전 층에서 20개 특성 맵이 출력된다면 3의 배수가 아니므로 작동하지 않음).
output = tf.nn.max_pool(images,
ksize=(1, 1, 1, 3),
strides=(1, 1, 1, 3),
padding='valid')이를 케라스 모델의 층으로 사용하고 싶으면 Lambda 층으로 감싸면 된다.
depth_pool = keras.layers.Lambda(
lambda X: tf.nn.max_pool(X, ksize=(1, 1, 1, 3), strides=(1, 1, 1, 3),
padding='valid'))마지막 풀링 층의 종류는 전역 평균 풀링 층(global average pooling layer, 이하 GAP)이다. 각 특성 맵의 평균을 계산하는 방법이다(특성 맵마다 하나의 숫자를 출력). 특성 맵의 대부분 정보를 잃지만 효과적으로 노드와 파라미터를 줄여 출력층에는 유용할 수 있다. 충분히 특성 맵의 채널 수가 많으면 적용해도 되지만, 채널 수가 적으면 Flatten이 유리하다. 명확한 채널 수 기준은 없지만 경험상 512차원 이상이 되면 GAP를 사용할만하다고 한다.
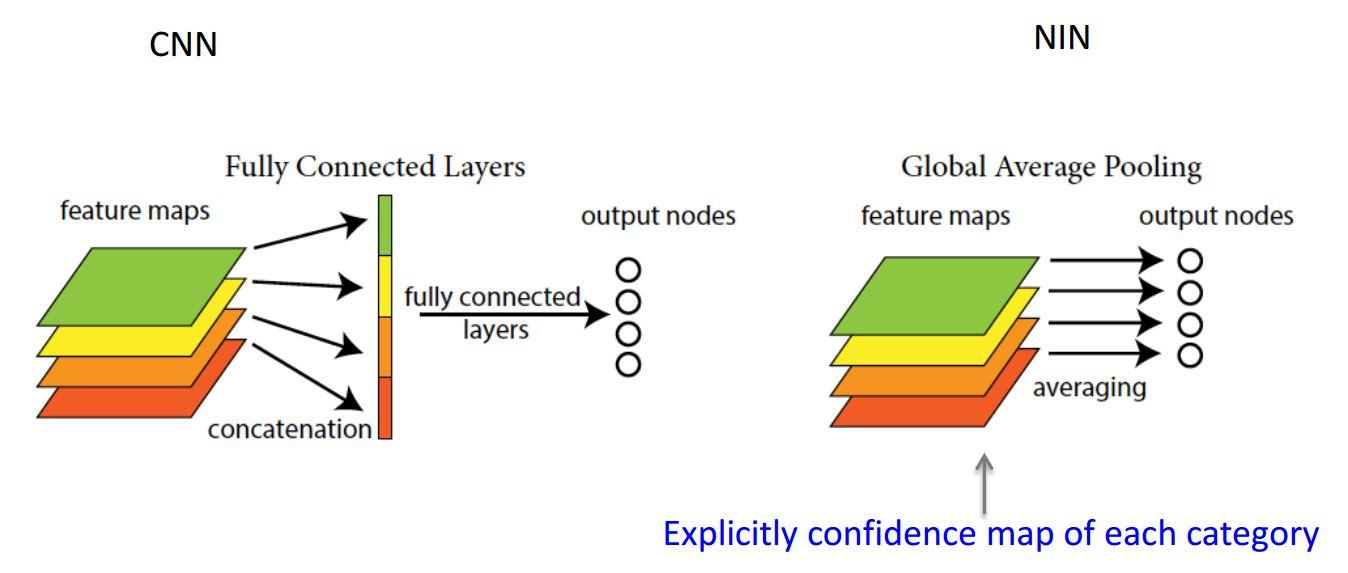
global_avg_pool = keras.layers.GlobalAvgPool2D()이는 공간 방향(높이와 너비)을 따라 평균을 계산하는 Lambda 층과 동등하다.
global_avg_pool = keras.layers.Lambda(lambda X: tf.reduce_mean(X, axis=[1, 2]))14.4 CNN 구조
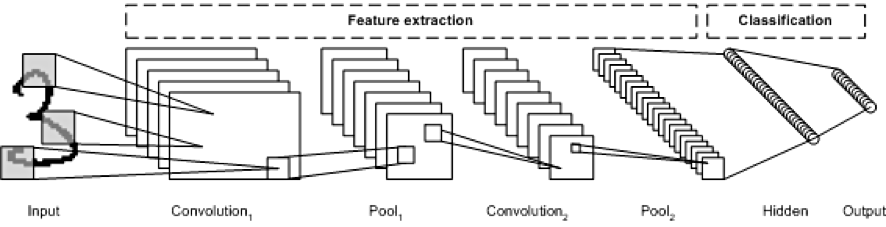
CNN은 네트워크를 통과하여 진행할수록 이미지는 점점 작아지지만, 합성곱 층 때문에 일반적으로 점점 더 깊어진다(=더 많은 특성 맵).
model = keras.models.Sequential([
keras.layers.Conv2D(filters=64, kernel_size=7, activation='relu', padding='same',
input_shape=[28, 28, 1]),
keras.layers.MaxPooling2D(2),
keras.layers.Conv2D(filters=128, kernel_size=3, activation='relu', padding='same'),
keras.layers.Conv2D(filters=128, kernel_size=3, activation='relu', padding='same'),
keras.layers.MaxPooling2D(2),
keras.layers.Conv2D(filters=256, kernel_size=3, activation='relu', padding='same'),
keras.layers.Conv2D(filters=256, kernel_size=3, activation='relu', padding='same'),
keras.layers.MaxPooling2D(2),
keras.layers.Flatten(),
keras.layers.Dense(128, activation='relu'),
keras.layers.Dropout(0.5),
keras.layers.Dense(64, activation='relu'),
keras.layers.Dropout(0.5),
keras.layers.Dense(10, activation='softmax')
])TIP!
합성곱 층에 너무 큰 커널을 사용하는 것은 실수!
보통 3 x 3 크기의 커널을 쌓되, 예외는 첫 번째 합성곱 층(5 x 5 크기의 커널을 보통 사용)
풀링 층 다음에 필터 개수를 2배로 늘리는 것이 일반적인 방법
밀집 네트워크는 샘플의 특성으로 1D 배열을 기대하므로 입력을 일괄로 펼쳐야 함
CNN의 장점은 대표적으로 2가지를 들 수 있다. 1) 파라미터 공유(parameter sharing), 2) 희소 연결(sparsity connection)이다. CNN은 동일한 필터를 입력 특성 맵 각 부분에 적용하기 때문에 이를 "공유"라고 표현한 것이다. 그리고 각 결과값은 오직 입력 특성 맵의 특정 부분에만 의존하기 때문에 "희소"라고 표현했다.
이렇게 되면 몇 픽셀 이동한 이미지도 유사한 속성을 갖게 되며(이동 불변성, translation invariance), 파라미터 수가 비교적 적기 때문에 오버피팅을 방지할 수 있게 된다. 예를 들어, vertical egde detector의 역할을 하는 필터가 있다고 가정해보자.
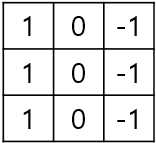
해당 필터는 입력 이미지의 어느 부분에 적용해도 이미지의 수직 부분을 강조하는 역할을 수행한다. 또한 모든 뉴런을 연결해야 하는 일반 신경망(Fully Connected Layer)보다 파라미터가 수가 적어 오버피팅의 위험이 줄어든다.
14.4.1 LeNet-5
LeNet-5 구조1는 1998년 얀 르쿤이 만들었으며 가장 널리 알려진 CNN 구조이다.
| 층 | 종류 | 특성 맵 | 크기 | 커널 크기 | 스트라이드 | 활성화 함수 |
| 입력 | 입력 | 1 | 32 x 32 | - | - | - |
| C1 | 합성곱 | 6 | 28 x 28 | 5 x 5 | 1 | tanh |
| S2 | 평균 풀링 | 6 | 14 x 14 | 2 x 2 | 2 | tanh |
| C3 | 합성곱 | 16 | 10 x 10 | 5 x 5 | 1 | tanh |
| S4 | 평균 풀링 | 16 | 5 x 5 | 2 x 2 | 2 | tanh |
| C5 | 합성곱 | 120 | 1 x 1 | 5 x 5 | 1 | tanh |
| F6 | 완전 연결 | - | 84 | - | - | tanh |
| 출력 | 완전 연결 | - | 10 | - | - | RBF |
- MNIST 이미지는 28 x 28 픽셀이지만 제로 패딩되어 32 x 32가 되고 네트워크에 주입되기 전 정규화 진행(네트워크의 나머지 부분은 패딩을 사용하지 않음)
- 평균 풀링 층에선 각 뉴런이 입력의 평균을 계산한 뒤 그 값에 학습되는 계숫값(특성 맵마다 하나씩 존재)을 곱함 -> 학습되는 값인 편향을 더함 -> 마지막으로 활성화 함수 적용
- C3에 있는 대부분의 뉴런은 S2의 (6개 맵 전체가 아닌) 3개 또는 4개 맵에 있는 뉴런에만 연결
- 출력층에선 입력과 가중치 벡터를 행렬 곱셈하는 대신 각 뉴런에서 입력 벡터와 가중치 벡터 사이의 유클리드 거리를 출력 -> 각 출력은 이미지가 얼마나 특정 숫자 클래스에 속하는지 측정
(요즘엔 잘못된 예측을 많이 줄여주고 그레이디언트 값이 크고 빠르게 수렴되기 때문에 크로스 엔트로피 비용 함수 선호)
14.4.2 AlexNet
AlexNet CNN 구조2는 알렉스 크리체프스키(Alex Krizhevsky), 일리아 서스케버(Ilya Sutskever), 제프리 힌턴이 만들었다. 이 구조는 더 크고 싶을 뿐 LeNet-5와 비슷하며, 처음으로 합성곱 층 위에 풀링 층을 쌓지 않고 합성곱 층끼리 쌓았다.
| 층 | 종류 | 특성 맵 | 크기 | 커널 크기 | 스트라이드 | 패딩 | 활성화 함수 |
| 입력 | 입력 | 3(RGB) | 227 x 227 | - | - | - | - |
| C1 | 합성곱 | 96 | 55 x 55 | 11 x 11 | 4 | valid | ReLU |
| S2 | 최대 풀링 | 96 | 27 x 27 | 3 x 3 | 2 | valid | - |
| C3 | 합성곱 | 256 | 27 x 27 | 5 x 5 | 1 | same | ReLU |
| S4 | 최대 풀링 | 256 | 13 x 13 | 3 x 3 | 2 | valid | - |
| C5 | 합성곱 | 384 | 13 x 13 | 3 x 3 | 1 | same | ReLU |
| C6 | 합성곱 | 384 | 13 x 13 | 3 x 3 | 1 | same | ReLU |
| C7 | 합성곱 | 256 | 13 x 13 | 3 x 3 | 1 | same | ReLU |
| F8 | 최대 풀링 | 256 | 6 x 6 | 3 x 3 | 2 | valid | - |
| F9 | 완전 연결 | - | 4,096 | - | - | - | ReLU |
| F10 | 완전 연결 | - | 4,096 | - | - | - | ReLU |
| 출력 | 완전 연결 | - | 1,000 | - | - | - | Softmax |
과대적합을 줄이기 위해 저자들은 2가지 규제 기법을 사용했다. 1) 훈련하는 동안 F9와 F10의 출력에 드롭아웃을 50% 비율로 적용, 2) 훈련 이미지를 랜덤으로 여러 간격으로 이동하거나 수평으로 뒤집고 조명을 바꾸는 식으로 데이터 증식(data augmentation)을 수행했다.
데이터 증식
데이터 증식은 진짜 같은 훈련 샘플을 인공적으로 생성하여 훈련 세트의 크기를 늘린다. 데이터 증식은 오버피팅을 줄이므로 규제 기법으로 사용된다. 원본 이미지에 다양한 변형(크기 변경, 이동, 회전 등)을 가하면 모델이 그림에 있는 물체의 위치, 방향, 크기 변화에 덜 민감해진다. 주의할 점은 원본 학습 이미지의 개수를 늘리는 것이 아니라 학습 시마다 개별 원본 이미지를 변형해서 학습을 수행한다는 것이다.
데이터 증식 유형에는 공간 레벨과 픽셀 레벨이 있다.
공간(Spatial) 레벨 변형
Flip: Vertical(up/down), Horizontal(left/right)
Crop: Center, Random
Affine: Rotate, Translate, Shear, Scale(Zoom)
픽셀(Pixel) 레벨 변형
Bright, Saturation, Hue, GrayScale, ColorJitter
Contrast
Blur, Gaussian Blur, Median Blur
Noise, Cutout
Histogram
Gamma
RGBShift
Sharpen
케라스에선 ImageDataGenerator 라는 패키지를 제공한다. 비교적 쉽게 데이터 증식을 수행하고 케라스와 통합되어 있어 편리한 데이터 전처리 파이프라인을 제공한다는 장점이 있다.
아래는 대표적인 ImageDataGenerator 변환 유형이다. Rotation이나 Shift, Zoom의 경우 엣지에 빈 공간이 생기기도 하는데 이때 fill_mode 라는 파라미터를 통해 빈 공간을 채운다.
Flip
- 좌우 반전: horizontal_flip=True
- 상하 반전: vertical_flip=True
Rotation
- rotation_range=45
- 임의의 -45 ~ +45도 사이 회전
Shift
- 좌우 이동: width_shift_range=0.2
- 상하 이동: height_shift_range=0.2
- 0 ~ 1 사이값 설정하여 좌우, 상하를 이동
Zoom
- zoom_range=[0.5, 1.5]
- 1보다 작은 값은 확장, 큰 값은 축소
Shear
- shear_range=45
- x축 또는 y축을 중심으로 0 ~ 45도 사이 변환
Bright
- brightness_range=(0.1, 0.9)
- brightness_range로 밝기 조절: 0에 가까울수록 어둡고, 1에 가까울수록 밝음
Channel Shift
- channel_shift_range=120
- R, G, B 픽셀값을 -120 ~ +120 사이의 임의값을 더하여 변환
Normalization
- featurewise_center=True: 각 R, G, B 픽셀값에서 개별 채널별 평균 픽셀값을 빼서 평균이 0이 되도록 유지
- featurewise_std_normalization=True: 각 R, G, B 픽셀값에서 개별 채널별 표준편차 픽셀값을 나눔
- .rescale=1/255.0: 딥러닝 입력은 비교적 작은 값은 선호하므로 픽셀값을 0 ~ 1 사이값으로 변환
fill_mode
1. nearest: 빈 공간에 가장 근접한 픽셀로 채움
2. reflect: 빈 공간만큼의 영역을 근처 공간으로 채우되 마치 거울로 반사되는 이미지를 보듯이 채움
3. wrap: 빈 공간을 이동으로 잘려나간 이미지로 채움
4. constant: 특정 픽셀값으로 채움(cval이란 파라미터 채우며 cval=0일 때 검은색 픽셀)
다시 AlexNet으로 돌아와서, C1과 C3층의 ReLU 단계 후에 바로 LRN(local response normalization)이라 부르는 경쟁적인 정규화 단계를 사용했다. 가장 강하게 활성화된 뉴런이 다른 특성 맵에 있는 같은 위치의 뉴런을 억제하는 구조다. 이는 특성 맵을 각기 특별하게 다른 것과 구분되게 하고, 더 넓은 시각에서 특징을 탐색하도록 만들어 결국 일반화 성능을 향상한다.
bi=ai(k+α∑jhighj=jlowa2j)−βwhere
jhigh=min(i+r2,fn−1)
jlow=max(0,i−r2)
bi: i 특성 맵, u행, v열에 위치한 뉴런의 정규화된 출력(이 식에선 현재 행과 열에 위치한 뉴런만 고려하므로 u와 v는 없음)
ai: ReLU 단계를 지나고 정규화 단계는 거치기 전인 뉴런의 활성화 값
k,α,β,r: 하이퍼파라미터로 k는 편향, r은 깊이 반경(depth radisu)
fn: 특성 맵 수
예를 들어, r=2이고 한 뉴런이 강하게 활성화되었다면 자신의 위와 아래의 특성 맵에 위치한 뉴런의 활성화를 억제한다. AlexNet에서 하이퍼파라미터는 r=2, α=0.00002, β=0.75, k=1로 설정되어 있다.
14.4.3 GoogLeNet
구글 리서치의 크리스찬 세게디(Christian Szegedy) 등이 개발한 GoogLeNet 구조3는 ILSVRC 2014 대회에서 톱-5 에러율을 7%이하로 낮추었다. 인셉션 모듈(inception module)이라는 서브 네트워크를 가지고 있어 GoogLeNet이 이전 구조보다 훨씬 효과적으로 파라미터를 사용한다(AlexNet보다 10배나 적은 파라미터, 거의 6백만 개).
아래는 인셉션 모듈의 구조이다. 모든 층마다 스트라이드1 및 same 패딩을 사용하고 있음을 기억하자.
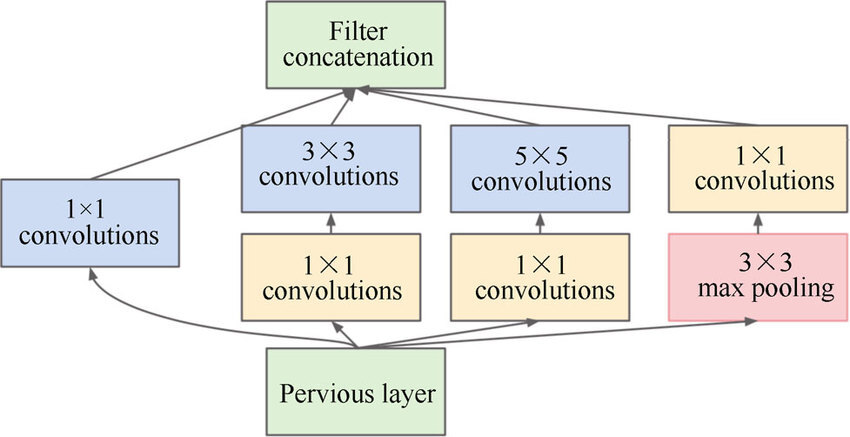
처음에 입력 신호가 복사되어 4개의 다른 층에 주입된다. 모든 합성곱 층은 ReLU 활성화 함수를 사용하고, 두 번째 합성곱 층은 각기 다른 커널 크기(1x1, 3x3, 5x5)를 사용해 다른 크기의 패턴을 잡는다. 모든 층마다 출력의 높이와 너비가 모두 입력과 같기 때문에 모든 출력을 깊이 연결 층(depth concatenation layer)에서 깊이방향으로 연결할 수 있다. 텐서플로로 구현하기 위해선 axis=3 (3은 깊이방향 축) 매개변수로 tf.concat() 연산을 사용하면 된다.
인셉션 모듈이 1x1 커널의 합성곱 층을 가지는 목적은 아래 3가지를 들 수 있다.
1. 공간상의 패턴을 잡을 수는 없지만 깊이 차원을 따라 놓인 패턴을 잡을 수 있음
2. 입력보다 더 작은 특성 맵을 출력하므로(예를 들어, 필터가 1개라면 기존 채널 값들이 하나의 수로 출력된다는 의미) 차원을 줄인다는 의미인 병목 층(bottleneck layer) 역할 담당
-> 연산 비용과 파라미터 개수를 줄여 훈련 속도를 높이고 일반화 성능 향상
3. 합성곱 층의 쌍 ([1x1, 3x3] 및 [1x1, 5x5])이 더 복잡한 패턴을 감지할 수 있는 한 개의 강력한 합성곱 층처럼 작동
GoogLeNet의 CNN 구조를 살펴보도록 하자. 네트워크를 하나로 길게 쌓은 구조이고 9개의 인셉션 모듈을 포함하고 있다. 모든 합성곱 층은 ReLU 활성화 함수를 사용한다.
(빨간색 사각형: Pooling / 초록색 사각형: LRN / 파란색 사각형: 합성곱 / 주황색 사각형: 소프트맥스)
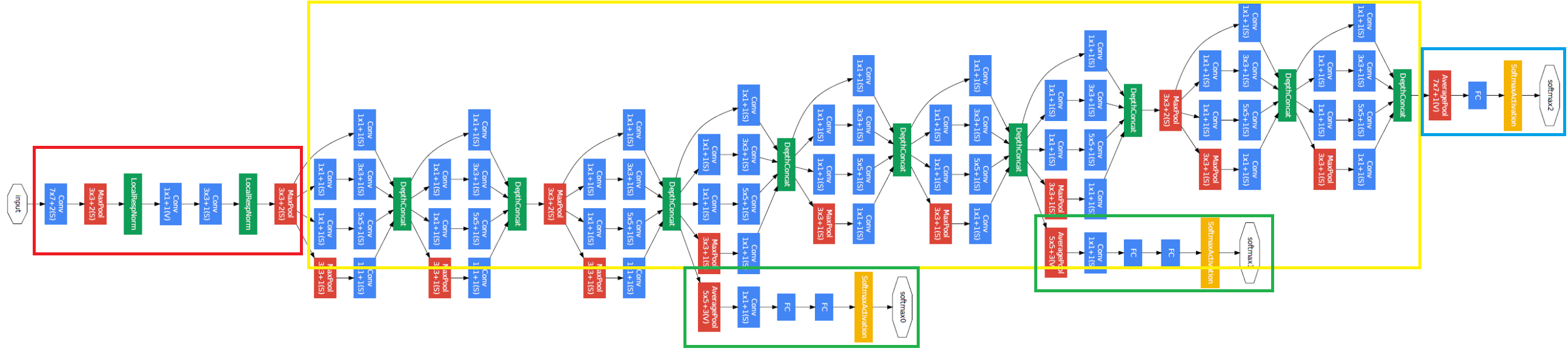
네트워크 로직을 살펴보면 아래와 같다.
- 처음 두 층은 계산의 양을 줄이기 위해 이미지의 높이와 너비를 4배로 줄인다(same 패딩에 스트라이드가 2이므로). 많은 정보를 유지하기 위해 첫 번째 층은 큰 크기의 커널(7x7)을 사용한다.
- LRN 층은 이전 층이 다양한 특성을 학습하도록 한다.
- 이어지는 두 개의 합성곱 층 중에서 첫 번째 층이 앞서 설명했듯 병목 층처럼 작동한다. 이 합성곱 쌍을 하나의 똑똑한 합성곱 층으로 생각할 수 있다.
- 다시 한 번 LRN 층이 이전 층으로 하여금 다양한 패턴을 학습하도록 한다.
- 최대 풀링 층이 계산 속도를 높이기 위해 이미지의 높이와 너비를 2배로 줄인다.
- 9개의 인셉션 모듈이 이어지고 차원 감소와 속도 향상을 위해 몇 개의 최대 풀링 층을 끼워넣는다.
- 전역 평균 풀링 층이 각 특성 맵의 평균을 출력한다. 여기선 공간 방향 정보를 모두 잃지만 남아 있는 공간 정보가 많지 않아 괜찮다. 이 층에서 수행된 차원 축소로 인해 (AlexNet처럼) CNN 위에 몇 개의 완전 연결 층을 둘 필요가 없다.
- 규제를 위한 드롭아웃 층 다음에 1000개의 유닛과 소프트맥스 활성화 함수를 적용한 완전 연결 층으로 클래스 확률 추정 값을 출력한다.
위 도식에서 3번째 및 6번째 인셉션 모듈 위에 연결된 2개의 부가적인 분류기를 볼 수 있다. 이들은 모두 평균 풀링 - 합성곱 - FC - FC - 소프트맥스로 구성되어 있다. 훈련하는 동안 여기에서의 손실이 (70% 정도 감해서) 전체 손실에 더해지며, 이는 그레이디언트 소실 문제를 줄이고 네트워크를 규제하기 위함이다. 하지만 효과는 비교적 적은 것으로 알려져 있다.
14.4.4 VGGNet
VGGNet은 캐런 시몬얀(Karen Simonyan)과 앤드루 지서만(Andrew Zisserman)이 개발했으며 ILSVRC 2014 대회 2등을 차지했다. VGGNet은 매우 단순하고 고전적인 구조로, 2개 또는 3개의 합성곱 층 뒤에 풀링 층이 나오고 다시 2개 또는 3개의 합성곱 층과 풀링 층이 등장하는 식이다(종류에 따라 총 16개 또는 19개의 합성곱 층 존재). 마지막 밀집 네트워크는 2개의 은닉층과 출력층으로 이루어진다. VGGNet은 많은 개수의 필터를 사용하지만 크기는 3x3 필터만 사용한다.
14.4.5 RestNet
카이밍 허(Kaiming He) 등은 잔차 네트워크(residual network, ResNet)를 사용해 ILSVRC 2015 대회에서 톱-5 에러율 3.6% 이하라는 기록으로 승리했다. RestNet4은 파라미터는 적어지고 네트워크는 더 깊어지는 일반적인 트렌드를 만들었다. 이런 깊은 네트워크를 훈련시킬 수 있는 핵심 요소는 스킵 연결(skip connection) 또는 숏컷 연결(shortcut connection)이다. 즉 어떤 층에 주입되는 신호가 상위 층의 출력에도 더해지는 것이다.
신경망을 훈련시킬 때는 목적 함수 f(x)를 모델링하는 것이 목표다. 만약 입력 x를 네트워크 출력에 더한다면 네트워크는 f(x) 대신 f(x)−x를 학습하게 되며 이를 잔차 학습(residual learning)이라고 한다.
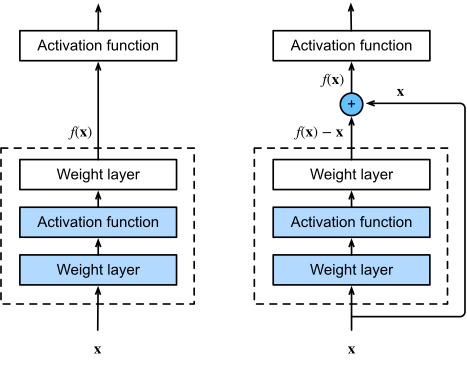
일반적인 신경망을 초기화할 때는 가중치가 0에 가깝기 때문에 네트워크도 0에 가까운 값을 출력한다. 스킵 연결을 추가하면 이 네트워크는 입력과 같은 값을 출력한다. 즉 초기에는 항등 함수(identity function)을 모델링하며 훈련 속도가 매우 빨라질 것이다.
또한 스킵 연결을 많이 추가하면 일부 층이 학습되지 않았더라도 네트워크는 훈련을 시작할 수 있다. 스킵 연결 덕분에 입력 신호가 잔차 네트워크에 손쉽게 영향을 미치게 된다. 심층 잔차 네트워크는 스킵 연결을 가진 작은 신경망인 잔차 유닛(residual unit, RU)을 쌓은 것으로 볼 수 있다.
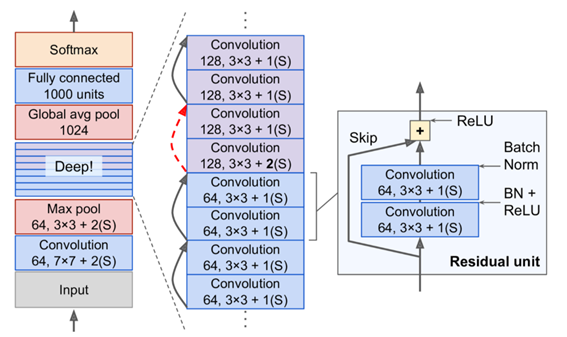
RestNet의 각 잔차 유닛은 배치 정규화(BN)와 ReLU, 3x3 커널을 사용하고 공간 정보를 유지하는(스트라이드 1, same 패딩) 2개의 합성곱 층으로 이루어져 있다.
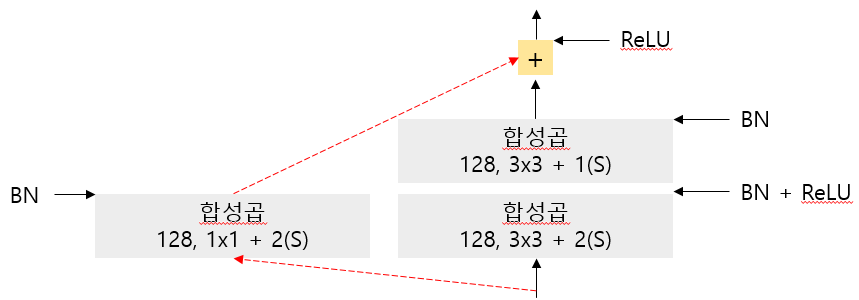
특성 맵의 수는 몇 개의 잔차 유닛마다 2배로 늘어나고 높이와 너비는 절반이 된다(스트라이드 2인 합성곱 층을 통해). 이때 입력과 출력의 크기가 다르기 때문에 입력이 잔차 유닛의 출력에 바로 더해질 수 없다(빨간색 파선). 이 문제를 해결하기 위해 스트라이드 2이고 출력 특성 맵의 수가 같은 1x1 합성곱 층으로 입력을 통과시킨다.
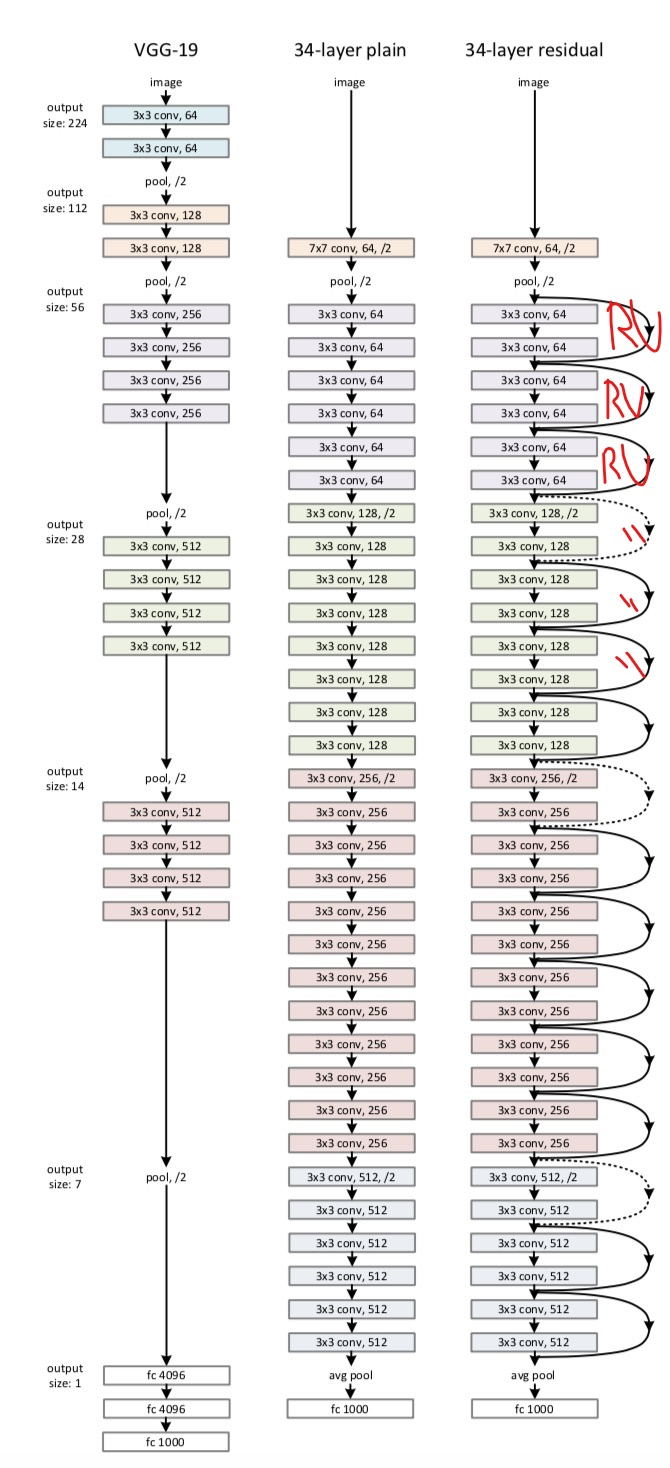
RestNet-34: 64개 특성 맵을 출력하는 3개 RU / 128개 맵의 4개 RU / 256개 맵의 6개 RU / 512개 맵의 3개 RU
RestNet-152: 256개 맵을 출력하는 3개 RU / 512개 맵의 8개 RU / 1024개 맵의 36개 RU / 2048개 맵의 3개 RU
14.4.6 Xception
2016년 프랑수아 숄레가 제안한 Xception5은 GoogLeNet 구조의 또 다른 변종이다. GoogLeNet과 ResNet의 아이디어를 합쳤지만 인셉션 모듈은 깊이별 분리 합성곱 층(depthwise separable convolution layer)이라는 특별한 층으로 대체했다. 정확히 말하면 Xception은 수정된 깊이별 분리 합성곱 층(modified depthwise separable convolution layer)을 사용했다. 일반적인 합성곱 층은 공간상의 패턴(타원 형태)과 채널 사이의 패턴(입+코+눈 = 얼굴)을 동시에 잡기 위해 필터를 사용한다. 분리 합성곱 층은 공간 패턴과 채널 사이 패턴을 분리하여 모델링할 수 있다고 가정한다.
오리지널 깊이별 분리 합성곱 층을 살펴보면 아래와 같다.
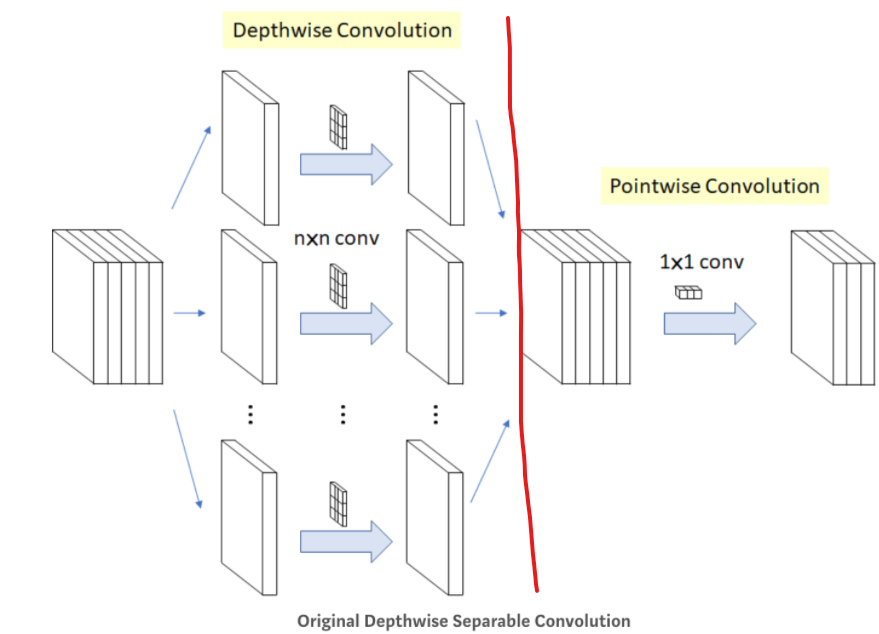
해당 층은 위처럼 2개의 부분으로 구성되는데, 첫 번째(Depthwise Convolution)는 하나의 공간 필터를 각 입력 특성 맵에 적용한다. 두 번째(Pointwise Convolution)는 깊이 필터(1x1)를 사용해 채널 사이 패턴만 조사한다. 분리 합성곱 층은 입력 채널마다 하나의 공간 필터만 가지기 때문에 입력층과 같이 채널이 너무 적은 층 다음에 사용하는 것을 피해야 한다. 이런 이유로 Xception 구조는 2개의 일반 합성곱 층으로 시작하며(Feature 2), 나머지는 분리 합성곱만 사용한다(총 34개).
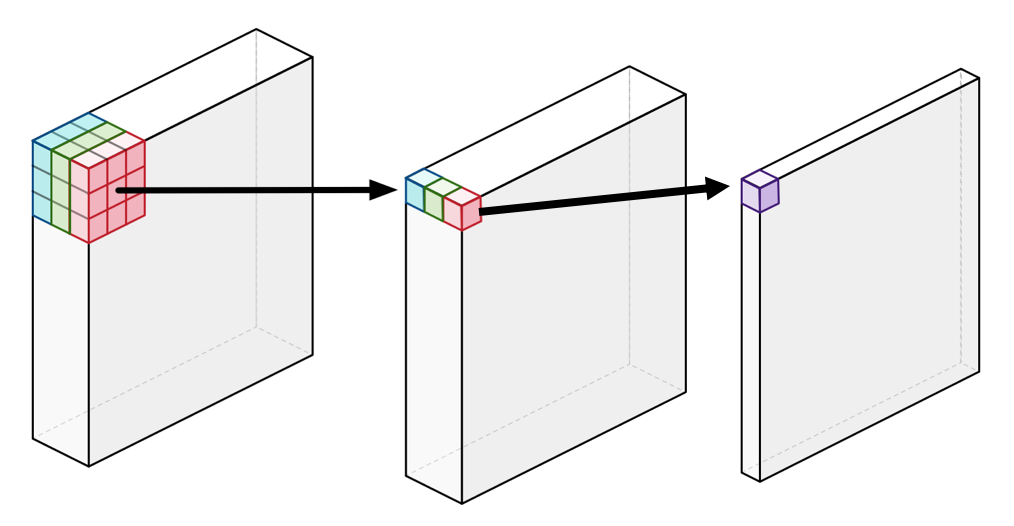
예를 들어, 256 x 256 x 3 의 input 이미지가 있을 때, 1) 256 x 256 x 1 을 3번 진행해서 concat을 하고, 2) pointwise convolution을 이용해 채널의 갯수를 1개로 줄인다(단순히 weighted sum 계산). 이 과정으로 convolution을 하면 약 9배 정도 빠르다고 한다.
Xception의 '수정된' 버전에서 달라진 점은 아래와 같다.
1. 연산 순서: 본래 depthwise -> pointwise 순서지만 pointwise -> depthwise 순서로 진행
2. Non-Linearity 유무: 인셉션의 경우, 첫 연산 후 ReLU(non-linearity)가 있지만 Xception은 중간에 적용하지 않음
3. Residual Connection이 거의 모든 Layer에 존재: 정확도 훨씬 높음
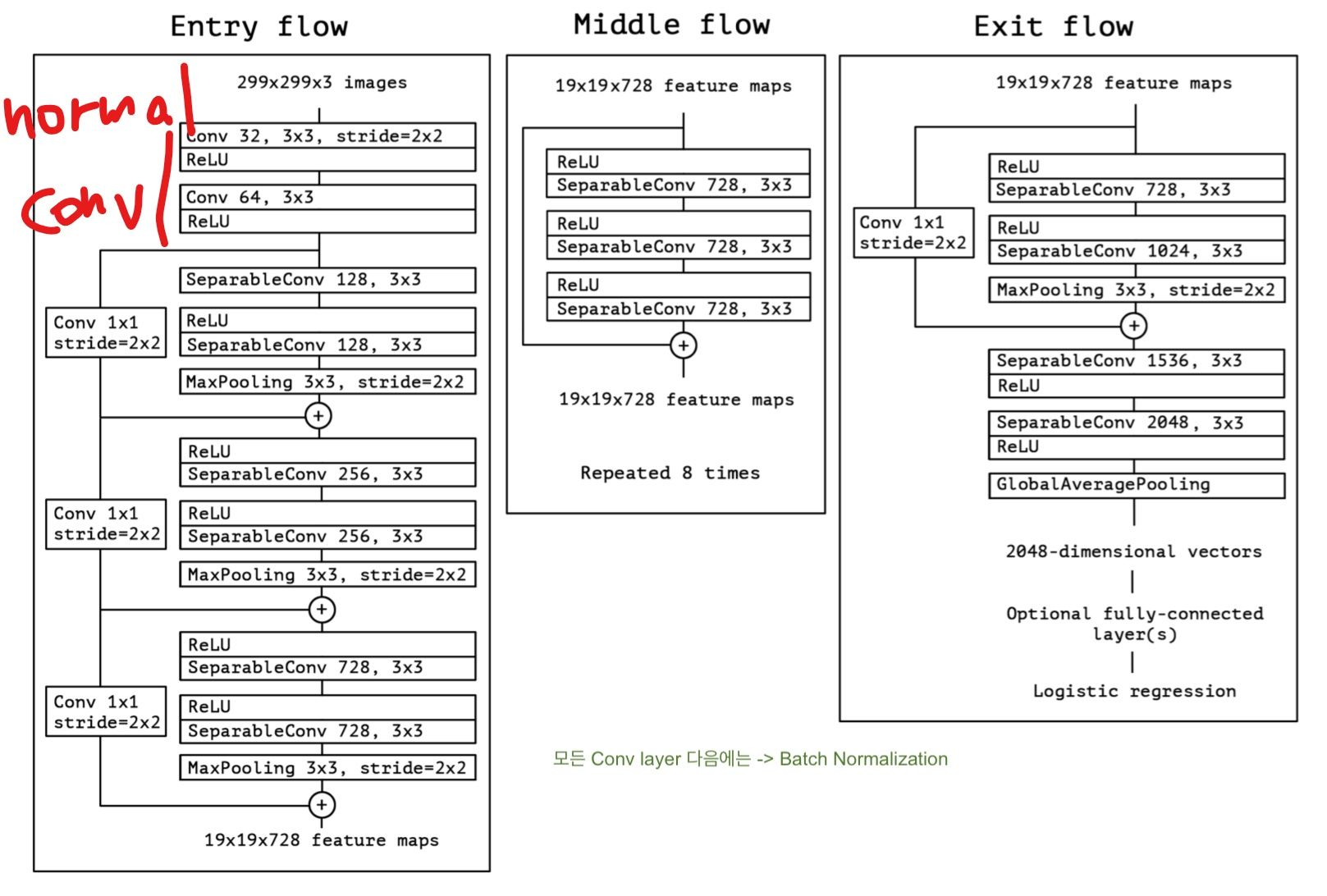
인셉션 모듈이 전혀 없는데 Xception을 GoogLeNet의 변종으로 간주하는 이유가 있다. 위에서 언급한 것처럼 인셉션 모듈은 1x1 필터를 사용한 합성곱 층을 포함한다. 이 층은 채널 사이 패턴만 감지한다. 하지만 위에 놓인 합성곱 층은 공간과 채널 패턴을 모두 감지하는 일반적인 합성곱 층이다. 따라서 인셉션 모듈을 (공간 패턴과 채널 패턴을 함께 고려하는) 일반 합성곱 층과 (따로 고려하는) 분리 합성곱 층의 중간 형태로 생각할 수 있다.
14.4.7 SENet
SENet은 인셉션 네트워크와 ResNet 같은 기존 구조를 확장하여 성능을 높였다. 인셉션 네트워크와 ResNet을 확장한 버전을 각각 SE-Inception과 SE-ResNet이라고 부른다. SENet은 원래 구조에 있는 모든 유닛(모든 인셉션 모듈 및 잔차 유닛)에 SE 블록이라는 작은 신경망을 추가한 것이다.
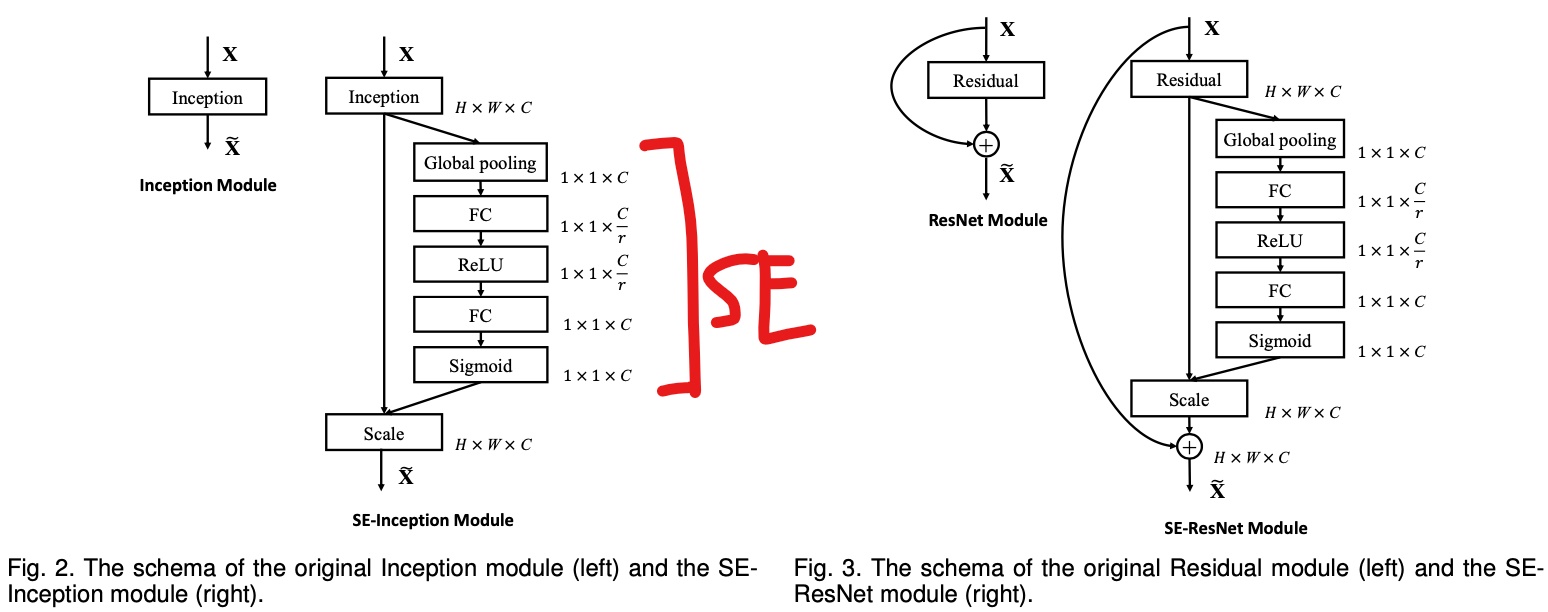
SE 블록이 추가된 부분의 유닛의 출력을 깊이 차원에 초점을 맞추어 분석한다(공간 패턴은 신경 X). 어떤 특성이 일반적으로 동시에 가장 크게 활성화되는지 학습한다. 그 다음 이 정보를 사용하여 특성 맵을 보정하게 된다. 예를 들어 SE 블록이 그림에서 함께 등장하는 입, 코, 눈을 학습할 수 있고, 우리가 사진에서 입과 코를 보았다면 눈도 볼 수 있다고 기대한다. 따라서 입과 코 특성 맵이 강하게 활성되고 눈 특성 맵만 크게 활성화되지 않았다면 이 블록이 눈 특성 맵의 출력을 높인다(정확히 말하면 관련 없는 특성 맵의 값을 줄인다).
하나의 SE 블록은 3개 층으로 구성된다. 전역 평균 풀링 층과 ReLU 활성화 함수를 사용하는 밀집 은닉층, 시그모이드 활성화 함수를 사용하는 밀집 출력 층이다.
처음에 전역 평균 풀링 층이 각 특성 맵에 대한 평균 활성화 값을 계산한다. 256개 특성 맵을 가진 입력이라면 각 필터의 전반적인 응답 수준을 나타내는 256개의 숫자가 출력된다. 다음 층은 256개보다 훨씬 적은 뉴런(일반적으로 특성 맵 개수보다 16배 적음)을 가지며 압축된다. 이 저차원 벡터(=하나의 임베딩)는 특성 응답의 분포를 표현한다. 해당 병목 층을 통해 SE 블록이 특성 조합에 대한 일반적인 표현을 학습하게 된다. 마지막으로 출력층은 이 임베딩을 받아 특성 맵마다 0과 1 사이의 하나의 숫자를 담은 보정된 벡터를 출력한다. 그다음 특성 맵과 이 보정된 벡터를 곱해 관련 없는 특성값을 낮추고 관련 있는 특성값은 그대로 유지한다.
14.5 케라스를 사용해 ResNet-34 CNN 구현하기
class ResidualUnit(keras.layers.Layer):
def __init__(self, filters, strides=1, activation='relu', **kwargs):
super().__init__(**kwargs)
self.activation = keras.activations.get(activation)
self.main_layers = [
keras.layers.Conv2D(filters, 3, strides=strides,
padding='same', use_bias=False),
keras.layers.BatchNormalization(),
self.activation,
keras.layers.Conv2D(filters, 3, strides=1,
padding='same', use_bias=False),
keras.layers.BatchNormalization()]
self.skip_layers = []
if strides > 1:
self.skip_layers = [
keras.layers.Conv2D(filters, 1, strides=strides,
padding='same', use_bias=False),
keras.layers.BatchNormalization()]
def call(self, inputs):
Z = inputs
for layer in self.main_layers:
Z = layer(Z)
skip_Z = inputs
for layer in self.skip_layers:
skip_Z = layer(skip_Z)
return self.activation(Z + skip_Z)위의 코드는 Feature 1을 그대로 구현한 것이다. call() 메서드에서 입력을 main_layers와 (skip_layers가 있다면) skip_layers에 통과시킨 후 두 출력을 더하여 활성화 함수를 적용한다.
이 네트워크는 연속되어 길게 연결된 층이기 때문에 Sequential 클래스를 사용해 RestNet-34 모델을 만들 수 있다(ResidualUnit 클래스를 준비해놓았으니 잔차 유닛을 하나의 층처럼 취급 가능).
model = keras.models.Sequential()
model.add(keras.layers.Conv2D(64, 7, strides=2, input_shape=[224, 224, 3],
padding='same', use_bias=False))
model.add(keras.layers.BatchNormalization())
model.add(keras.layers.Activation('relu'))
model.add(keras.layers.MaxPool2D(pool_size=3, strides=2, padding='same'))
prev_filters = 64
for filters in [64] * 3 + [128] * 4 + [256] * 6 + [512] * 3:
# 필터 개수가 이전 RU와 동일할 경우 스트라이드를 1로, 아니면 2로 설정
strides = 1 if filters == prev_filters else 2
model.add(ResidualUnit(filters, strides=strides))
prev_filters = filters
model.add(keras.layers.GlobalAvgPool2D())
model.add(keras.layers.Flatten())
model.add(keras.layers.Dense(10, activation='softmax'))14.6 케라스에서 제공하는 사전훈련된 모델 사용하기
keras.applications 패키지에 준비되어 있는 사전훈련된 모델을 불러올 수 있다. 아래는 이미지넷 데이터셋에서 사전훈련된 ResNet-50 모델을 로드하는 것이다.
model = keras.applications.resnet50.ResNet50(weights='imagenet')ResNet-50 모델은 224 x 224 픽셀 크기의 이미지를 기대하기 때문에 텐서플로의 tf.image.resize() 함수로 앞서 적재한 이미지의 크기를 바꿔야 한다.
images_resized = tf.image.resize(images, [224, 244])사전훈련된 모델은 이미지가 적절한 방식으로 전처리되었다고 가정하며, 경우에 따라 0에서 1 사이 또는 -1에서 1 사이의 입력을 기대한다. 이를 위해 모델마다 이미지를 전처리해주는 preprocess_input() 함수를 제공한다. 이 함수는 픽셀값이 0에서 255 사이라고 가정하여 (앞에서 0에서 1사이로 바꿨기 때문에) images_resized 에 255를 곱해야 한다.
inputs = keras.applications.resnet50.preprocess_input(images_resized * 255)Y_proba = model.predict(inputs)통상적인 구조대로 출력 Y_proba 는 행이 하나의 이미지고 열이 하나의 클래스인 행렬이다. 최상위 K개의 예측에 대해 클래스 이름과 예측 클래스의 추정 확률을 출력하려면 decode_predictions() 함수를 사용하면 된다. 각 이미지에 대해 최상위 K개의 예측을 담은 리스트를 반환하는데, 각 예측은 클래스 아이디, 이름, 확률을 포함한 튜플이다.
top_K = keras.applications.resnet50.decode_predictions(Y_proba, top=3)
for image_index in range(len(images)):
print('이미지 #{}.'format(image_index))
for class_id, name, y_proba in top_K[image_index]:
print(' {} - {:12s} {:2.f}%'.format(class_id, name, y_proba * 100))
print()
14.7 사전훈련된 모델을 사용한 전이 학습
사전훈련된 Xception 모델을 사용해 꽃 이미지를 분류하는 모델을 훈련해보자.
import tensorflow_datasets as tfds
dataset, info = tfds.load('tf_flowers', as_supervised=True, with_info=True)
dataset_size = info.splits['train'].num_examples # 3670
class_names = info.features['label'].names
n_classes = info.features['label'].num_classes # 5with_info=True 로 지정하면 데이터셋에 대한 정보를 얻을 수 있는데, 여기선 데이터셋의 크기와 클래스의 이름을 얻는다.
test_split, valid_split, train_split = tfds.Split.TRAIN.subsplit([10, 15, 75])
test_set = tfds.load('tf_flowers', split=test_split, as_supervised=True)
valid_set = tfds.load('tf_flowers', split=valid_split, as_supervised=True)
train_set = tfds.load('tf_flowers', split=train_split, as_supervised=True)해당 CNN 모델은 224 x 224 크기 이미지를 기대하므로 크기를 조정해야 한다.
def preprocess(image, label):
resized_image = tf.image.resize(image, [224, 224])
final_image = keras.applications.xception.preprocess_input(resized_image)
return final_image, label
batch_size = 32
train_set = train_set.shuffle(1000)
# prefetch(): 학습 데이터를 나눠서 읽어오기 때문에 첫 번째 데이터를 GPU에서 학습하는 동안 두 번째 데이터를 CPU에서 준비할 수 있어 리소스 유휴 상태 감소
train_set = train_set.map(preprocess).batch(batch_size).prefetch(1)
valid_set = valid_set.map(preprocess).batch(batch_size).prefetch(1)
test_set = test_set.map(preprocess).batch(batch_size).prefetch(1)이제 이미지넷에서 사전훈련된 Xception 모델을 로드한다. include_top=False 로 지정하여 네트워크 최상층에 해당하는 전역 평균 풀링 층과 밀집 출력 층을 제외시킨다.
base_model = keras.applications.xception.Xception(weights='imagenet',
include_top=False)
avg = keras.layers.GlobalAveragePooling2D()(base_model.output)
output = keras.layers.Dense(n_classes, activation='softmax')(avg)
model = keras.Model(inputs=base_model.input, outputs=output)훈련 초기에는 사전훈련된 층의 가중치를 동결하는 것이 좋다.
for layer in base_model.layers:
layer.trainable = False마지막으로 모델을 컴파일하고 훈련을 시작하면 된다.
optimizer = keras.optimizer.SGD(lr=0.2, momentum=0.9, decay=0.01)
model.compile(loss='sparse_categorical_crossentropy', optimizer=optimizer,
metrics=['accuracy'])
history = model.fit(train_set, epochs=5, validation_data=valid_set)모델을 몇 번의 에포크 동안 훈련하면 검증 정확도가 75~80%에 도달하고 더 나아지지 않을 것이다. 이는 새로 추가한 최상위 층이 잘 훈련되었다는 것을 의미하므로 모든 층(또는 상위 층 일부)의 동결을 해제하고 훈련을 계속한다. (주의!) 층을 동결하거나 해제할 때 모델을 다시 컴파일해야 하며 사전훈련된 가중치가 훼손되는 것을 피하기 위해 훨씬 작은 학습률을 사용한다.
for layer in base_model.layers:
layer.trainable = True
optimizer = keras.optimizers.SGD(lr=0.01, momentum=0.9, decay=0.001)
model.compile(...)
history = model.fit(...)이제 해당 모델은 테스트 세트에서 95%의 정확도를 달성할 것이다.
추가: EfficientNet
EfficientNet6은 2019년 발표된 모델로 기존 모델보다 더 작은 파라미터로 SOTA를 달성한 모델이다.
CNN 모델에서 크기를 키워 성능을 높이는 방법은 아래 3가지가 있다.
1. 네트워크의 깊이(depth)를 깊게
2. 필터 갯수(channel width)를 많게
3. 입력 이미지의 해상도(resolution)을 높게
결론부터 말하면 EfficientNet은 위의 3가지를 최적으로 조합하여 모델 성능을 극대화한 모델이라 할 수 있다. 이렇게 조합하는 것을 Compound Scaling이라고 부르는데, EfficientNet은 주어진 모델의 메모리와 FLOPs 제약 내에서 최대의 정확도를 가지는 모델을 찾고자 했다.
아래는 위 3가지 차원을 각각 변화시켰을 때 정확도 변화를 나타낸 것이다.
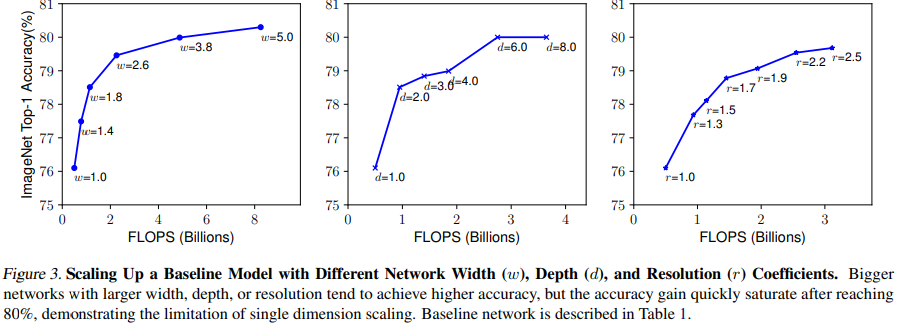
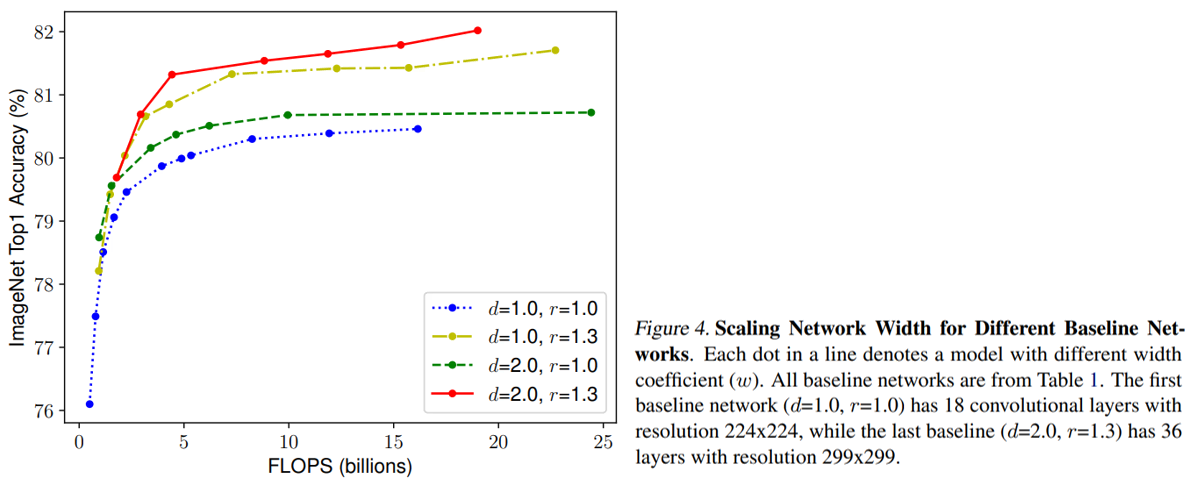
아래는 각 차원의 조합을 달리했을 때 성능을 비교한 그래프이다.
- 이미지 해상도가 높을 경우 더 큰 Receptive field가 더 많은 픽셀을 포함하는 비슷한 feature들을 잘 잡아낼(capture) 수 있다.
- 더 많은 필터 수를 가지면 높은 이미지 해상도의 많은 픽셀들에 대해 세밀한 패턴을 잘 잡아낼 수 있다.
depth와 resolution을 각각 1.0으로 고정하고 width만 증가시켰을 때 정확도 성능은 80%에서 수렴했다. 반대로 depth는 2.0, resolution은 1.3으로 고정하고 width만 변화시켰을 때는 비슷한 FLOPs 상에서 더 나은 성능을 보였다.
이처럼 논문 저자는 단일 차원의 scaling이 아니라 복합적인 차원의 균형 및 조정이 필요하다는 직관을 얻었다. 이를 도출하는 식은 아래와 같다.

- ϕ: 자원이 추가될 때(EfficientNetB0~B7) model scaling을 비례해서 증가시킬 계수
- 각 dimension과 FLOPs의 관계: d ∝ FLOPs, w ∝ FLOPs2, r ∝ FLOPs2
- 총 FLOPs: (α⋅β2⋅γ2)ϕ 와 비례
- FLOPs를 ϕ에 따라 2배씩 증가하도록 설정하기 위해 (α⋅β2⋅γ2)=2로 제한
EfficientNet 아키텍처 구조는 아래와 같다.
이후 챕터(분류와 위치 추정)는 조금 더 공부하고 정리를 할 계획입니다.
참조
Deep Learning - Andrew NG
https://wansook0316.github.io/ds/dl/2020/09/07/computer-vision-12-Xception.html
https://nbviewer.org/github/Hyunjulie/KR-Reading-Image-Segmentation-Papers/blob/master/Xception%EC%84%A4%EB%AA%85%EA%B3%BC%20Pytorch%EA%B5%AC%ED%98%84.ipynb
- Gradient-based learning applied to document recognition [본문으로]
- ImageNet Classification with Deep Convolutional Neural Networks [본문으로]
- Going Deeper with Convolutions [본문으로]
- Deep Residual Learning for Image Recognition [본문으로]
- Xception: Deep Learning with Depthwise Separable Convolutions [본문으로]
- EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks [본문으로]
'문돌이 존버 > 데이터 분석' 카테고리의 다른 글
| 핸즈온 머신러닝 2 복습하기(챕터 16: RNN과 어텐션을 사용한 자연어 처리) (2) | 2024.01.05 |
|---|---|
| 핸즈온 머신러닝 2 복습하기(챕터 15: RNN과 CNN을 사용해 시퀀스 처리하기) (1) | 2023.10.05 |
| 핸즈온 머신러닝 2 복습하기(챕터 11: 심층 신경망 훈련하기) (0) | 2022.01.01 |
| 버트(BERT) 개념 간단히 이해하기 (2) | 2021.11.17 |
| 트랜스포머(Transformer) 간단히 이해하기 (2) (2) | 2021.11.11 |



