본 글은 "딥 러닝을 이용한 자연어 처리 입문"을 학습하며 작성한 것입니다. 중간중간 제가 이해한 내용을 좀 더 풀어서 썼습니다.
바다나우 어텐션
지난 번 닷-프로덕트 어텐션에 이어 이번 시간에는 바다나우 어텐션을 살펴보도록 하겠습니다. 아래 어텐션 함수는 대체적으로 동일하되 다른 점이 하나 있습니다. 바로 Query가 디코더 셀의 t 시점의 은닉 상태가 아닌 t-1 시점의 은닉 상태라는 것입니다.
어텐션 함수
Attention(Q, K, V) = Attention Value
t = 어텐션 메커니즘이 수행되는 디코더 셀의 현재 시점을 의미.
Q = Query : t-1 시점의 디코더 셀에서의 은닉 상태
K = Keys : 모든 시점의 인코더 셀의 은닉 상태들
V = Values : 모든 시점의 인코더 셀의 은닉 상태들
1) 어텐션 스코어(Attention Score) 구하기

그림에서도 알 수 있듯이 디코더의 t 시점 은닉 상태가 아닌 t-1 시점의 은닉 상태 st−1를 사용합니다. 바다나우 어텐션의 스코어 함수는 아래와 같습니다.
score(st−1,hi)=WTatanh(Wbst−1+Wchi)
여기서 Wa,Wb,Wc는 학습 가능한 가중치 행렬입니다. 그리고 h1,h2,h3,h4는 하나의 행렬 H로 두면 수식은 아래처럼 변경됩니다.
score(st−1,H)=WTatanh(Wbst−1+WcH)
아래 그림을 통해 위 수식을 보면 이해가 쉬울 것입니다. WcH(주황색 박스)는 Wbst−1(초록색 박스)는 아래와 같습니다.
이들을 더한 후에는 하이퍼볼릭탄젠트 함수를 지나도록 합니다.
tanh(Wbst−1+WcH)
이제 WTa와 곱하여 st−1와 h1,h2,h3,h4의 유사도가 기록된 어텐션 스코어 벡터 et를 얻습니다.
et=WTatanh(Wbst−1+WcH)

2) 소프트맥스 함수를 통한 어텐션 분포(Attention Distribution) 구하기
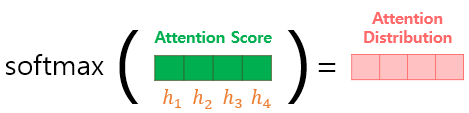
et에 소프트맥스 함수를 적용하면 모든 값의 합이 1이 되는 확률 분포를 얻어내고, 이를 어텐션 분포라고 부릅니다. 또 각각의 값은 어텐션 가중치(Attention Weight)라고 합니다.
3) 어텐션 값(Attention Value) 구하기
지금까지 얻은 정보들을 하나로 합치는 단계로, 각 인코더의 은닉 상태와 어텐션 가중치값들을 곱하고 최종적으로 모두 더합니다.
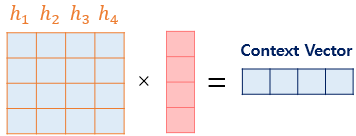
인코더의 문맥을 포함하고 있기 때문에 이를 컨텍스트 벡터(context vector)라고 부릅니다.
4) st를 구하기
아래는 어텐션 메커니즘에서의 LSTM 작동 방식입니다. 기존의 LSTM 작동 방식과 달리 현재 시점의 입력 xt가 특이합니다. 컨텍스트 벡터와 현재 시점의 입력 단어 임베딩 벡터를 연결(concatenate)하여 새로운 입력으로 사용한 모습입니다. 기존 LSTM에선 현재 시점의 입력은 단어 임베딩 벡터 하나에 불과했습니다.
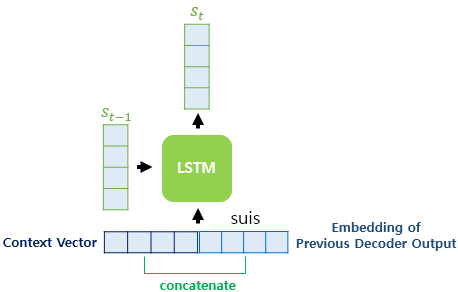
사실 concatenate는 닷-프로덕트 어텐션 메커니즘에서도 사용했던 방식입니다. 다른 점은 바다나우 어텐션에서 컨텍스트 벡터를 다음 단어를 예측하는 데 입력 단어에 합친다는 것입니다. 닷-프로덕트 어텐션에선 이전 단어의 예측값인 st에 컨텍스트 벡터를 합치고(vt), 가중치 행렬 Wc와 곱한 뒤 하이퍼볼릭탄젠트 함수를 거쳐 예측 벡터인 ^st를 얻었습니다.
이후의 과정은 어텐션 메커니즘을 사용하지 않는 경우, 즉 일반적인 LSTM을 실행시키는 것과 동일합니다.
실제 파이토치 튜토리얼 코드에서 설명하는 Attention 디코더는 바다나우 어텐션을 사용하고 있습니다. 아래의 그림을 보면 디코더의 입력 부분(input)을 임베딩하고 임베딩값(embedded)과 인코더 은닉 상태들과 어텐션 가중치를 곱하고 더하여(bmm) 얻어진 어텐션 값(attn_applied)과 합치는 것을 알 수 있습니다. 합친 결과(attn_combine)를 RNN셀(여기선 GRU) 입력으로 사용하는 것이죠.
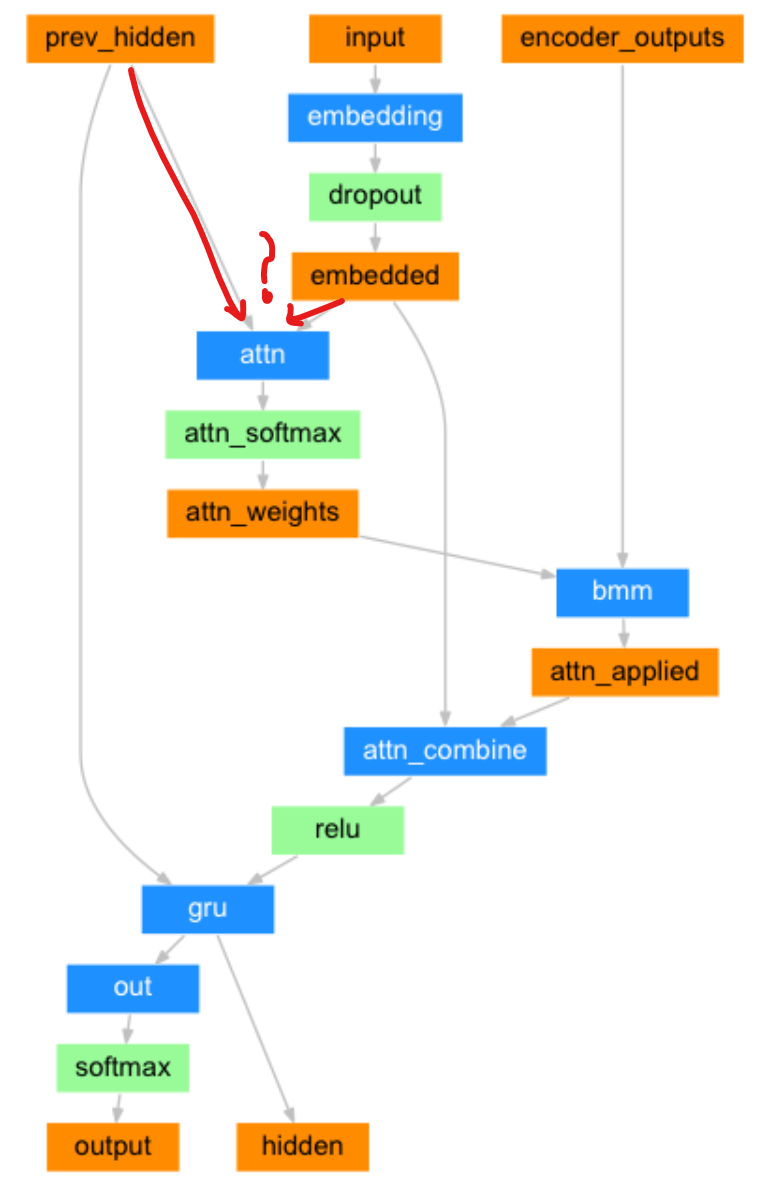
다만, 위 도식에서 이해가 되지 않는 부분은 어텐션 값(=컨텍스트 벡터)을 만드는 과정입니다. 디코더 입력과 디코더 은닉 상태(prev_hidden)을 가지고 어텐션 값을 만드는데, 본래 어텐션 메커니즘에선 인코더의 모든 은닉 상태와 디코더 은닉 상태를 사용했었습니다. 해당 부분은 파이토치 커뮤니티(영어, 한국어)에 질문을 남겨 아는대로 본 글에 내용을 추가하겠습니다.
바다나우 어텐션을 구현한 파이토치 튜토리얼은 여기서 확인할 수 있습니다. 아래는 해당 튜토리얼에서 가져온 Attention 디코더 구조입니다.
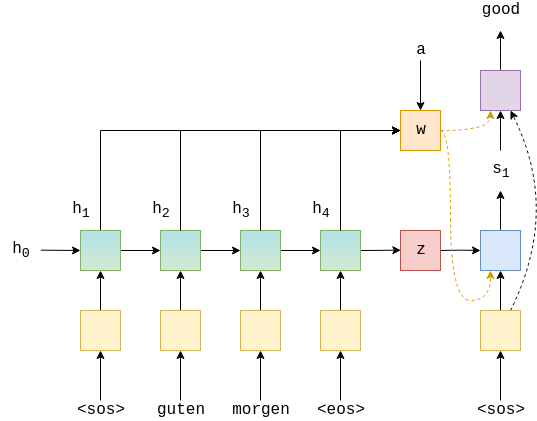
위에서 "good"이란 단어를 예측하기 위해 GRU 셀을 거쳐 나온 1) 은닉 상태값 s1, 2) 어텐션 값 w, 3) 디코더 입력 임베딩 크기를 FC 레이어에 넘겨줍니다. 해당 관련 코드를 잠깐만 살펴보면 아래와 같습니다.
def foward(self, input, hidden, encoder_outputs):
...
embedded = self.dropout(self.embedding(input)) # embedded = [1, batch size, emb dim]
...
output, hidden = self.rnn(rnn_input, hidden.unsqueeze(0))
...
weighted = torch.bmm(a, encoder_outputs)
weighted = weighted.permute(1, 0, 2) # weighted = [1, batch size, enc hid dim * 2]
...
output, hidden = self.rnn(rnn_input, hidden.unsqueeze(0))
# output = [seq len, batch size, dec hid dim * n directions]
...
embedded = embedded.squeeze(0)
output = output.squeeze(0)
weighted = weighted.squeeze(0)
prediction = self.fc_out(torch.cat((output, weighted, embedded), dim = 1))위에서 weighted.shape[-1]이 enc hid dim * 2인 이유는 bidirectional RNN 구조이기 때문
여기서 주의할 점은 위에서 FC 레이어에 넘겨주는 3가지가 값 자체가 아닌 크기를 의미한다는 것입니다. torch.cat(, dim=1) 을 하면 최종 크기는 (batch size, dec hid dim + (enc hid dim * 2) + emb dim)이 됩니다.
아래 어텐션 메커니즘의 도식을 살펴보면 FC 레이어를 2번 사용하면서 최종 예측값을 구했는데요. 위의 바다나우 어텐션 튜토리얼 코드에선 FC 레이어를 사용하지 않고 크기만 모두 연결한 뒤에 마지막에 FC 레이어에 전달하는 구조입니다.
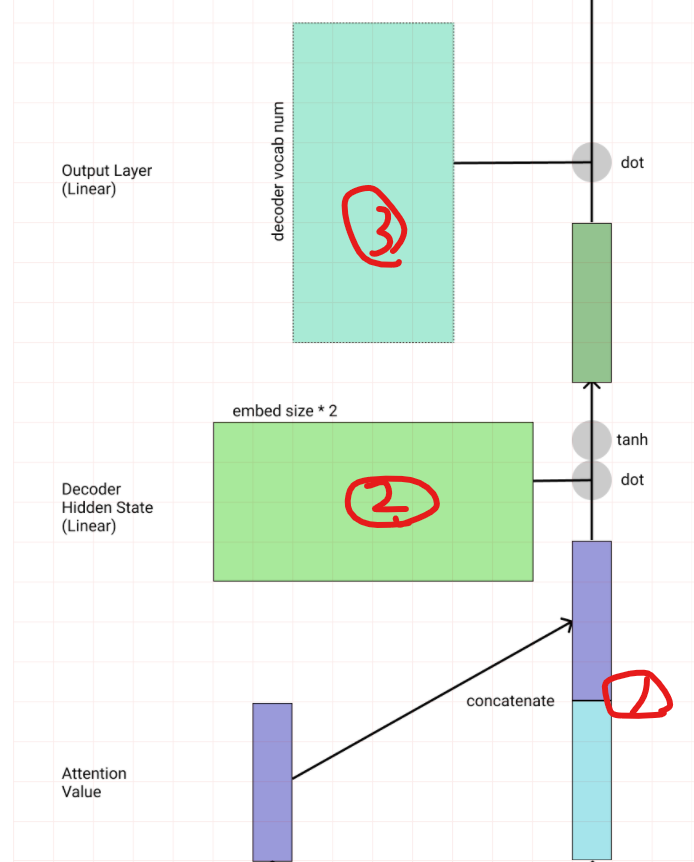
사실 제가 참고한 튜토리얼 코드가 정확한지는 모르겠습니다만.. 더 적절한 코드를 찾지 못했는데 혹시 위 내용 중에 틀린 것이 있다면 댓글 부탁드리겠습니다^^
참조
딥 러닝을 이용한 자연어 처리 입문(https://wikidocs.net/73161)
'문돌이 존버 > 데이터 분석' 카테고리의 다른 글
| (Explainable AI) SHAP에 대해 알아보자! (2) | 2021.07.23 |
|---|---|
| (Explainable AI) Shapley Value에 대해 알아보자! (4) | 2021.07.22 |
| 어텐션 메커니즘(Attention Mechanism) 간단히 이해하기 (3) | 2021.07.02 |
| 핸즈온 머신러닝 2 복습하기(챕터 7: 앙상블 학습과 랜덤 포레스트) (0) | 2021.06.18 |
| 핸즈온 머신러닝 2 복습하기(챕터 8: 차원 축소) (0) | 2021.06.17 |



