오늘은 저번 ggplot2 기초 따라잡기에 이어 Facet 함수를 활용하여 범주형 변수가 다른 변수에 미치는 영향력을 확인하는 방법을 소개하겠습니다. 즉 범주형 변수에 의해 구분되는 그룹별로 그래프를 작성하여 비교하는 것입니다. 그룹별 그래프에 큰 차이가 없다면 범주형 변수의 영향력이 미미하다고 볼 수 있겠죠.
아래에서 사용한 함수 facet_wrap() 은 데이터를 구분하려는 변수가 하나인 경우에 사용됩니다.
ggplot(data=mpg) +
geom_point(mapping=aes(x=displ, y=hwy))+facet_wrap(~ class)
위 그림을 살펴보면 class="2seater" 인 그래프에 유난히 데이터가 적은 것을 발견할 수 있습니다. 따라서 이 데이터들을 무시하고 3열이 아닌 2열 형태의 그래프를 그려보았습니다. facet_wrap(~ class, ncol=2) 처럼 열 개수를 정해주면 됩니다.
library(dplyr)
mpg_1 <- mpg%>%filter(class != "2seater")
ggplot(data=mpg_1) +
geom_point(mapping=aes(x=displ, y=hwy))+facet_wrap(~ class, ncol=2)
그래프의 열이나 행 순서를 설정하려면 아래와 같이 dir="v" 를 추가하거나 작성하지 않으면 되는데요. 작성하지 않을 경우 디폴트 값으로 행 단위로 배치되고, 추가하면 열 단위로 배치됩니다.
ggplot(data=mpg_1) +
geom_point(mapping=aes(x=displ, y=hwy))+facet_wrap(~ class, ncol=2, dir="v")
지금까지 구분하려는 변수가 1개일 때를 설명했는데요. 구분하려는 변수가 1개 이상인 경우에는 facet_grid() 함수를 쓰면 됩니다. 변수 1개인 경우 이 함수를 사용하려면 하나의 행을 구성하여 옆으로 나란히 배치되는 facet_grid(.~x), 하나의 열을 구성하여 위아래로 배치되는 facet_grid(y~.) 형태를 사용하면 됩니다.
두 변수를 사용할 경우, facet_grid(y~x) 의 형태를 사용하여 변수 y의 범주를 행으로, x의 범주를 열로 배열하게 됩니다. 두 변수는 아래와 같이 cyl 과 drv 를 사용할 것이며 각각 1개씩 클래스를 제외하겠습니다.
mpg_2 <- mpg%>%filter(cyl != 5, drv != "r")
# ggplot 그래프 역시 변수로 할당 가능
my_plot <- ggplot(data=mpg_2) +
geom_point(mapping=aes(x=displ, y=hwy))
my_plot
그럼 이제 drv 와 cyl 두 범주 변수를 기준으로 그래프를 그려보겠습니다. 위에서 클래스를 1개씩 제외했기 때문에 drv 는 2개 그룹으로, cyl 은 3개 그룹으로 나옵니다.
my_plot+facet_grid(drv~cyl)
연속형 변수를 faceting 하기 위해서는 우선 범주형 변수로 변환시켜야 합니다. 아래 cut_() 함수를 이용하면 됩니다. 각각 무엇을 의미하는지 예제를 통해 쉽게 살펴봅시다.
cut_interval(x, n, length)
cut_width(x, width, boundary)
cut_number(x, n) # x=numeric vector, n=# of intervalscut_interval은 n 이나 length 를 파라미터로 설정할 수 있는데요. 차이점을 보시면 n 은 실제 값을 기준으로 고르게 나누고, length 는 실제 값이 아니라 각 간격의 길이를 바탕으로 나누고 그 길이를 반환합니다. 즉 1~100 숫자를 10인 간격으로 나눈 것이고 각 간격 안에 무슨 숫자가 들어있는지 출력하지 않습니다.
cut_interval(1:100, n = 10)
cut_interval(1:100, length = 10)

cut_width 는 보통 width 파라미터로 각 간격을 결정합니다. 아래에서 0.2로 설정했기 때문에 2개 숫자 간의 차이는 0.2죠. 여기서 주의할 점은 boundary 파라미터인데, 이를 설정해주면 boundary=0 기준 간격에서 양 옆 숫자의 크기가 설정한 값만큼 작아진 것을 볼 수 있습니다. 여기선 0.1로 설정하여 첫 간격을 보면 본래 [1, 1.2]인데 [0.9, 1.1]로 변화된 것을 확인할 수 있습니다.
cut_width(1:100, width=0.2, boundary = 0.1)
cut_width(1:100, width=0.2, boundary = 0)

cut_number는 n 크기만큼 x 를 고르게 나누고 간격 안의 숫자를 출력합니다.
cut_number(c(1, 2, 3, 4), n=2)
cut_number(c(1, 2, 3, 4), n=3)
이제 샘플 데이터 airquality 를 살펴보도록 합시다. cut_number(airquality$Wind, n=4) 를 통해 Wind 변수 전체를 4만큼 고르게 나누었습니다.
airquality
airquality$wind_d <- cut_number(airquality$Wind, n=4)
ggplot(data=airquality) +
geom_point(mapping=aes(x=Solar.R, y=Ozone))+
facet_wrap(~wind_d)
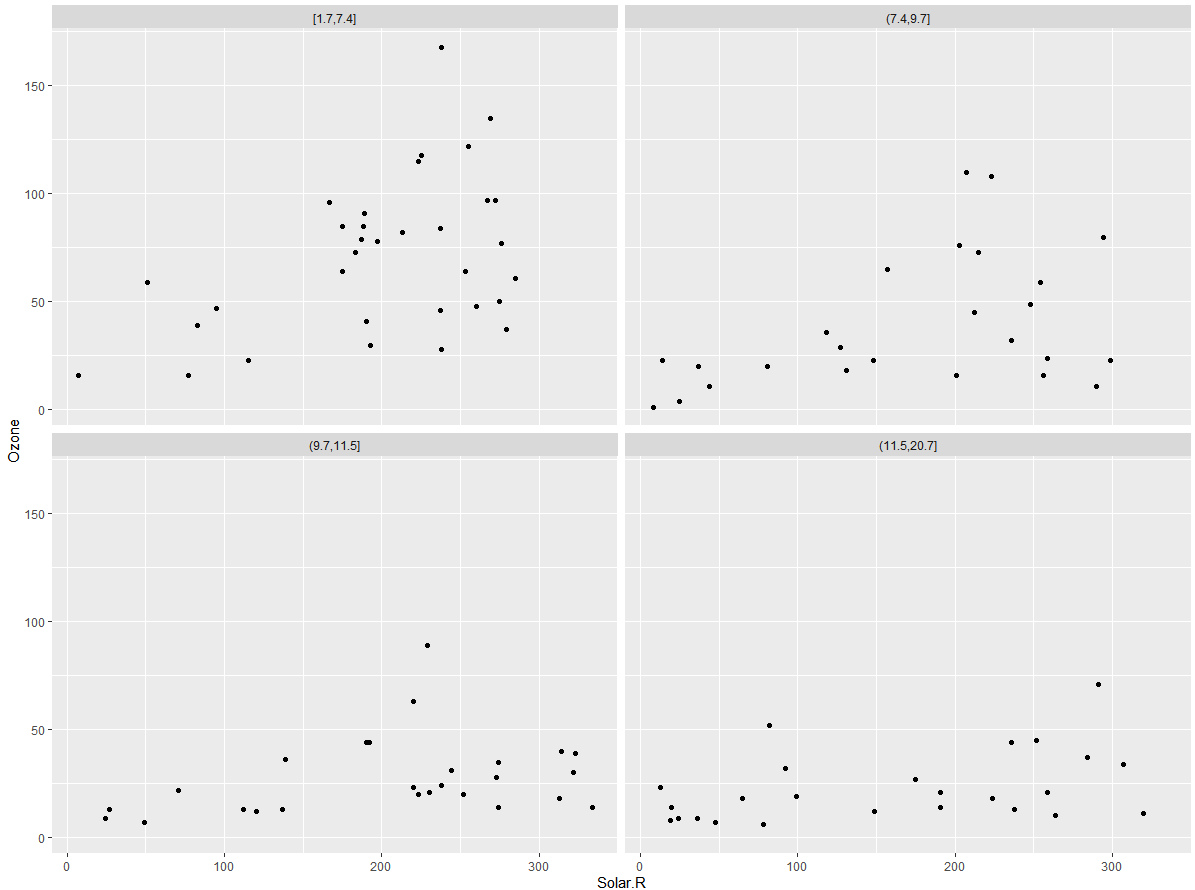
Facet 함수의 장점은 점들이 많이 겹치는 경우에 더 명확하게 다른 변수의 정보를 확인할 수 있다는 것입니다. 아래는 Facet 함수를 사용하지 않은 채 점의 색깔와 사이즈로 wind_d 변수를 나타낸 것입니다. 점들이 겹쳐 있어 관계를 확인하는 데 어려움이 있죠. 하지만 위의 Facet 함수를 사용한 그래프를 사용하면 wind_d 변수에 따른 차이점을 비교적 명확히 파악할 수 있습니다.

'문돌이 존버 > R 기초 스터디' 카테고리의 다른 글
| R ggplot2 geom 객체 기초 따라잡기 (0) | 2020.11.12 |
|---|---|
| R ggplot2 활용법 기초 따라잡기 (0) | 2020.11.10 |
| R 데이터프레임(Dataframe) 생성 기초 따라잡기 1탄 (0) | 2020.11.10 |
| R 문자열(string) 처리 기초 따라잡기 (0) | 2020.11.07 |
| R 데이터 생성(벡터) 방법 기초 따라잡기 (0) | 2020.11.05 |



