반응형
오늘은 저번에 진행한 R 데이터 생성(벡터) 방법 기초 따라잡기에 이은 두 번째 시간으로, 문자열을 처리하는 다양한 함수에 대해 알아보겠습니다.
# nchar(): 문자열을 구성하는 문자 개수 계산
x=c("Kim", "Ban", "Hwang")
nchar(x)
nchar("중어중문학과")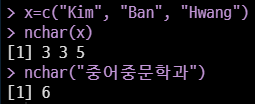
paste() 함수를 통해 문자열을 숫자와 결합할 수 있으며 결합하는 데 sep="" 파라미터를 통해 띄어쓰기, 기호 등을 자유롭게 추가할 수 있습니다. 그런데 문자열이 2개밖에 없고 결합할 숫자는 3개인 경우, 다시 순환을 하며 첫 문자열에 마지막 숫자가 붙게 됩니다.
# paste(): 문자열의 결합
paste("china", 1:3, sep="")
paste(c("china", "literature"), 1:3, sep="-")
paste(letters, collapse="")
paste(LETTERS, collapse="")
substr() 함수를 통해 문자열의 일부분을 선택합니다. 파이썬과 비교했을 때 주의할 점은
1. 인덱스가 0부터 시작하지 않는다.
2. stop에 해당하는 인덱스도 포함된다.
# substr(): 문자열에서 일부분 선택
x <- c("중어중문학과", "인문데이터과학", "졸업준비생")
substr(x, start=1, stop=2)
strsplit() 함수는 문자열을 특정 기호를 바탕으로 분리하는 역할을 수행합니다. 파이썬의 split() 함수와 똑같죠.
# strsplit(): 문자열의 분할
x <- c("Shanghai, SH", "Bejing, BK", "Chicago, IL")
y <- strsplit(x, split=",")
y
다음은 문자열을 소문자(tolower) 또는 대문자(toupper)로 변환하는 함수입니다. 위에서 배운 substr() 함수와 함께 사용하여 이름 맨 앞글자만 대문자로 변환해봤습니다.
# touuper()과 tolower()
x <- c("Kim", "jun", "hwang")
y <- toupper(x)
tolower(y)
substr(x, 1, 1) <- toupper(substr(x, 1, 1))
728x90
반응형
'문돌이 존버 > R 기초 스터디' 카테고리의 다른 글
| R ggplot2 geom 객체 기초 따라잡기 (0) | 2020.11.12 |
|---|---|
| R ggplot2 Facet(ing) 함수 기초 따라잡기 (0) | 2020.11.11 |
| R ggplot2 활용법 기초 따라잡기 (0) | 2020.11.10 |
| R 데이터프레임(Dataframe) 생성 기초 따라잡기 1탄 (0) | 2020.11.10 |
| R 데이터 생성(벡터) 방법 기초 따라잡기 (0) | 2020.11.05 |



