추천 시스템을 공부해야 할 계기가 생겨 여러 가지 방법론과 샘플 코드 등을 살펴보고 있습니다. 부딪치지 않고서야 어떤 데이터를 사용해야 할지, 어떤 알고리즘이 적당한지 단번에 알 수는 없습니다. 클론 코딩을 많이 하며 한줄 한줄 이해해나가야 하죠^^
그래서 이번 시간엔 추천 시스템 중 콘텐츠 기반(contents based)의 방법을 사용해보겠습니다. 콘텐츠 기반이란, 말 그대로 하나의 아이템을 여러 특성으로 분류하여 내용물을 분석하겠다는 것을 말하는데요. 예를 들어, 한 사용자가 특정 영화를 봤다고 한다면 이 사실에서 끝나는 것이 아니라, 그 영화를 설명할 수 있는 호러, 비극, 주연, 감독 등 정보를 파악하는 것입니다. 이후 다른 영화를 추천할 때 같은 감독, 주연이 나오면 추천 우선순위가 올라가겠죠.
사용할 데이터셋은 아마도(?) 쇼핑몰의 상품(신발, 셔츠 등)과 그에 대한 설명입니다. 소개해드릴 방법은 한 외국인의 글을 참고한 것입니다. 그리고 저는 구글 코랩(Colab)에서 코드를 돌렸습니다.
코랩에서 데이터를 읽으려면 필요한 명령어입니다.
from google.colab import drive
drive.mount('/content/drive')기본적으로 필요한 모듈들을 임포트합니다. 특히 문장을 분석할 것이기 때문에 Tfidf와 Cosine similarity 관련 모듈이 꼭 필요합니다.
import pandas as pd
import numpy as np
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import linear_kernel데이터셋을 살펴보면 description 컬럼 안에 아이템 명과 그에 대한 설명이 "-" 표시로 구분되어 있습니다. "-" 앞의 어구가(예: Active classic boxers) 아이템명이라고 생각하면 됩니다.
df = pd.read_csv('/content/drive/My Drive/Colab Notebooks/RS/sample-data.csv')
df.head()
간단하게 데이터셋의 크기를 살펴봅니다. 500개의 아이템이 들어있네요.
df.shape아이템에 대한 설명이 얼마나 길지 살펴보겠습니다. 꽤나 길다는 것을 확인할 수 있고 우리가 하나의 문서로 취급하는 대상입니다.
df.iloc[0].description본격적으로 Tfidf 벡터를 구하고 문서 간 유사도를 출력하는 과정입니다. 각각 TfidfVectorizer 함수와 linear_kernel 함수를 사용하면 구할 수 있습니다.
tf = TfidfVectorizer(analyzer='word', ngram_range=(1, 3), min_df=0, stop_words='english')
tfidf_matrix = tf.fit_transform(df['description'])
cosine_similarities = linear_kernel(tfidf_matrix, tfidf_matrix)
results = {}
for idx, row in df.iterrows():
similar_indices = cosine_similarities[idx].argsort()[:-100:-1] # 유사도가 높은 아이템 순서대로 정렬(index를 리턴)
similar_items = [(cosine_similarities[idx][i], df['id'][i]) for i in similar_indices]
results[row['id']] = similar_items[1:] # 자기 자신을 제외한 나머지 아이템들 간의 유사도 저장
# 아이템명 뽑기
def item(id):
return df.loc[df['id'] == id]['description'].tolist()[0].split(' - ')[0]
def recommend(item_id, num):
print("Recommeding " + str(num) + " products simliar to " + item(item_id) + "...")
print("-" * 20)
# 특정 아이템과 유사한 상품을 num 개 추천
recs = results[item_id][:num]
for rec in recs:
print("Recommended: " + item(rec[1]) + " (score:" + str(rec[0]) + ")")
recommend(item_id=11, num=5)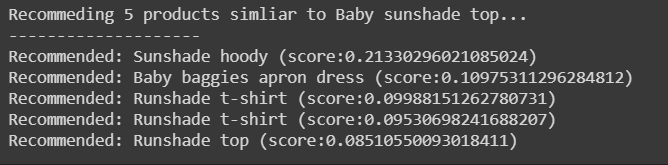
TfidfVectorizer 함수의 파라미터를 살펴보겠습니다.
먼저, analyzer 는 학습단위를 결정합니다. word 와 char 총 2가지로 나뉘는데, 글자 그대로 해석하면 됩니다. word 는 단어 단위, char 은 글자 단위입니다.
min_df 는 최소 문서의 수 빈도값을 설정합니다. 다시 말해, 해당 단어가 나타난 문서의 수를 가리키고, 최소 2개 문서 이상에 나타날 것을 원하면 min_df=2 가 되겠죠.
ngram_range는 단어묶음의 범위를 결정합니다. 위에선 ngram_range(1, 3) 로 설정했으니, 단어묶음을 1개에서 3개까지 고려하라는 것입니다. 디폴트값은 1개로, 일반적으로 단어 1개를 단위로 합니다. 하지만 ngram_range(1, 2) 는 "go", "go to" 처럼 go와 to를 하나의 묶음으로 봅니다. 어떤 단어의 경우 2~3개가 묶여야 제대로 해석되기 때문에 ngram_range 를 3개까지 늘려보면 좋을 듯 합니다.
stopwords도 설정할 수 있는데 기본적으로 영어는 제공됩니다. 한국어의 경우, 따로 stopwords 변수를 만들어서 파라미터로 넣어주어야 합니다.
* 참고
위 코드에서 코사인 유사도 인덱스를 뽑을 때 argsort()[:-100:-1] 가 의미하는 것이 무엇인지 살펴보기 위해 아래처럼 실험을 했습니다. argsort() 는 코사인 유사도를 높은 순서대로 인덱스를 반환하는데요.
x = np.array([[9, 2, 3, 1, 4],
[4, 5, 6, 5, 7],
[7, 6, 5, 1, 3],
[1, 3, 5, 8, 9],
[5, 7, 9, 1, 2]])
print(x.argsort())
# shape(n, m)일 때, [:-p:-q] 의 경우, 1) 첫 번째 row부터 n-p 번째 row까지, 2) 1번에서 나온 범위(해당 row는 포함x)를 제외한 범위에서 q 번째까지의 row를 제외한 row들
print(x.argsort()[:-3])
print(x.argsort()[:-3:-2])
print(x.argsort()[:-3:-1])
전체 코드는 제 깃허브에서 확인하실 수 있습니다!
GitHub - aeddung/ML-DL
Contribute to aeddung/ML-DL development by creating an account on GitHub.
github.com
참고: chan-lab.tistory.com/27
'문돌이 존버 > 데이터 분석' 카테고리의 다른 글
| 핸즈온 머신러닝 2 연습 문제 코드(Decision Tree) (0) | 2021.01.03 |
|---|---|
| 핸즈온 머신러닝 2 복습하기(챕터 6: 결정 트리) (0) | 2021.01.03 |
| 핸즈온 머신러닝 2 연습 문제 코드 (SVM) (0) | 2020.11.15 |
| 핸즈온 머신러닝 2 복습하기(챕터 5: 서포트 벡터 머신) (1) | 2020.11.14 |
| 핸즈온 머신러닝 2 복습하기(챕터 4: 모델 훈련) (0) | 2020.09.30 |



