문돌이 존버/데이터 분석
멀티 레이블 분류(랜덤포레스트 및 딥러닝 keras 사용기) feat.파이썬
애뚱
2020. 3. 4. 00:17
반응형
이번에는 제가 파이썬 스터디를 하면서 함께 공부한 자료를 공유하려고 합니다. 대단한 것은 아니고 머신러닝, 딥러닝 강의를 보며 배운 기법들을 다 써보자 하는 마인드로 코드를 작성했습니다. 데이터는 월간 데이콘 대회의 것을 참고했고 멀티 레이블을 분류하는 문제(천체 유형 분류)를 선택했습니다.
데이콘 2 천체 유형 분류 대회: 원본 csv 파일
[과학] 월간 데이콘 2 천체 유형 분류 대회
출처 : DACON - Data Science Competition
dacon.io
1. type = Source type : 천체의 분류 (예측을 해야 하는 변수입니다.)
2. psfMag = Point spread function magnitudes : 먼 천체를 한 점으로 가정하여 측정한 빛의 밝기입니다.
3. fiberMag = Fiber magnitudes : 3인치 지름의 광섬유를 사용하여 광스펙트럼을 측정합니다. 광섬유를 통과하는 빛의 밝기입니다.
4. petroMag = Petrosian Magnitudes : 은하처럼 뚜렷한 표면이 없는 천체에서는 빛의 밝기를 측정하기 어렵습니다. 천체의 위치와 거리에 상관없이 빛의 밝기를 비교하기 위한 수치입니다.
5. modelMag = Model magnitudes : 천체 중심으로부터 특정 거리의 밝기입니다.
6. fiberID = 관측에 사용된 광섬유의 구분자
import pandas as pd
import numpy as np
import sklearn
from sklearn.preprocessing import StandardScaler
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
train = pd.read_csv(r'C:\Users\User\Desktop\Python_study\대회 자료\train.csv', index_col=0)
train.head(5)
train.shape
# 천체 분류 값 확인
train['type'].unique()
# feature 타입 확인
train.dtypes
# nan값 확인
train.isnull().sum()
# 트레이닝, 테스트 데이터 분리
x = train.drop(columns=['type', 'fiberID'], axis=1)
y = train['type']
x.shape
# scaling, pca 없이 raw 데이터로 진행
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(x, y, test_size=0.3, random_state=777)
print(len(X_train))
print(len(X_test))
# 랜덤포레스트 without tuning
rf = RandomForestClassifier(random_state=17)
rf.fit(X_train, y_train)
forest_predictions = rf.predict(X_test)
accuracy_score(y_test, forest_predictions)forest_predictions = rf.predict(X_test)
accuracy_score(y_test, forest_predictions)
# add tuning
from sklearn.model_selection import GridSearchCV
forest_params = {'max_depth': range(5, 15),
'max_features': ['auto', 'sqrt', 'log2']}
# 그리드 서치 적용
locally_best_forest = GridSearchCV(RandomForestClassifier(n_estimators=20,
random_state=17, n_jobs=-1), forest_params, cv=3, verbose=1)
locally_best_forest.fit(X_train, y_train)
print("Best params:", locally_best_forest.best_params_)
print("Best cross validaton score", locally_best_forest.best_score_)
# max_depth = 14 / max_features = auto
rf = RandomForestClassifier(class_weight='balanced', criterion='gini', max_depth=14, max_features='auto', n_estimators=100,
random_state=17, n_jobs=-1)
rf.fit(X_train, y_train)
forest_predictions = locally_best_forest.predict(X_test)
accuracy_score(y_test, forest_predictions)
# 스케일링 1
sc = StandardScaler()
train_x_scaled = sc.fit_transform(X_train)
test_x_scaled = sc.fit_transform(X_test)
from sklearn.decomposition import PCA
pca = PCA(n_components=10) # 비율로 하면 train, test 차원 수가 달라짐: 10차원 / 5차원
train_x_pca = pca.fit_transform(X_train)
test_x_pca = pca.fit_transform(X_test)
pd.DataFrame(test_x_pca).head()
rf = RandomForestClassifier(random_state=17)
rf.fit(train_x_pca, y_train)
forest_predictions = rf.predict(test_x_pca)
accuracy_score(y_test, forest_predictions)
# 스케일링 2
from sklearn.preprocessing import MinMaxScaler
minmax = MinMaxScaler()
train_x_scaled1 = minmax.fit_transform(X_train)
test_x_scaled1 = minmax.fit_transform(X_test)
# without tuning
rf = RandomForestClassifier(random_state=17)
rf.fit(train_x_scaled1, y_train)
forest_predictions = rf.predict(test_x_scaled1)
accuracy_score(y_test, forest_predictions)
from sklearn.ensemble import BaggingClassifier
from sklearn.tree import DecisionTreeClassifier
# 배깅과 페이스팅을 위한 BaggingClassifier
bag_clf = BaggingClassifier(
DecisionTreeClassifier(), n_estimators=200,
max_samples=100, bootstrap=True, n_jobs=-1)
bag_clf.fit(X_train, y_train)
y_pred1 = bag_clf.predict(X_test)
accuracy_score(y_test, y_pred1)
# 그래디언트 부스팅 (시간 굉장히 많이 소요)
from sklearn.ensemble import GradientBoostingClassifier
gbc_clf = GradientBoostingClassifier(random_state=0, learning_rate=0.2)
gbc_clf.fit(X_train, y_train)
y_pred2 = gbc_clf.predict(X_test)
print(accuracy_score(y_test, y_pred2))
# 나이브 베이즈(정확률 매우 낮음)
from sklearn.naive_bayes import GaussianNB
gnb = GaussianNB()
gnb.fit(X_train, y_train)
y_pred3 = gnb.predict(X_test)
print(accuracy_score(y_test, y_pred3))
# 딥러닝 Keras 사용
import numpy as np
import pandas as pd
import tensorflow as tf
import sklearn
from sklearn.preprocessing import StandardScaler
df = pd.read_csv(r'C:\Users\User\Desktop\Python_study\대회 자료\train.csv', index_col=0)
x = df.drop(columns=['type', 'fiberID'], axis=1)
y = df['type']
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(x, y, test_size=0.3, random_state=777)
unique_labels = df['type'].unique()
label_dict = {val: i for i, val in enumerate(unique_labels)}
label_dict
y_train = y_train.replace(label_dict)
y_test = y_test.replace(label_dict)
optimizer = tf.keras.optimizers.Adam(learning_rate=0.0003)
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import Dropout
model = Sequential()
model.add(Dense(256*2, input_dim=len(x.columns), activation='relu')),
model.add(Dropout(0.1)),
model.add(Dense(256*2, activation='relu')),
model.add(Dense(256*1, activation='relu')),
model.add(Dropout(0.15))
model.add(Dense(256*1, activation='relu')),
model.add(Dense(256*1, activation='relu')),
model.add(Dropout(0.1)),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(32, activation='relu'),
model.add(Dense(19, activation='softmax'))
model.compile(optimizer=optimizer,
loss='sparse_categorical_crossentropy',
metrics=['acc'])
# epochs 200번 - 3시간 소요
model.fit(X_train, y_train, epochs=200, batch_size=256, validation_split=0.1)
model.evaluate(X_test, y_test, batch_size=256)
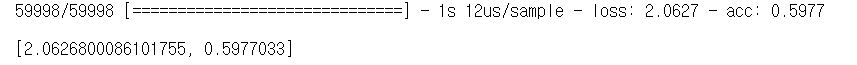
정확도는 scaling, pca, tuning 아무것도 없이 진행한 랜덤포레스트의 것이 약 87%로 가장 높았네요. 이것저것 시도해보니 오히려 정확도가 떨어지더라구요...
위의 스크린샷은 딥러닝 keras를 돌린 결과인데 성능이 썩 좋지 않네요. layer가 낮아서인지, 활성화방식(relu)이 부적절한 것인지 그 이유는 잘 모르겠지만 어쨌든 여러 기법을 시도해보니 좋은 경험이었습니다.
728x90
반응형